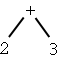
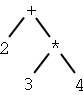
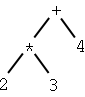
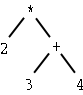
These lecture notes are my own notes that I made in order to use during the lecture, and it is approximately what I will be saying in the lecture. These notes may be brief, incomplete and hard to understand, not to mention in the wrong language, and they do not replace the lecture or the book, but there is no reason to keep them secret if someone wants to look at them.
Today:
More about syntactical analysis, "parsiing" (Swedish: syntaktisk analys, parsning)
We will build a simple compiler that translates from infix notation of expressions to postfix. Examples of expressions that we want to translate:
| Infix notation | Tree | Value | Postfix notation | Prefix notation | Function notation | LISP |
|---|---|---|---|---|---|---|
| 2 + 3 |
| 5 | 2 3 + | + 2 3 | plus(2, 3) | (plus 2 3) |
| 2 + 3 * 4 |
| 14 | 2 3 4 * + | + 2 * 3 4 | plus(2, times(3, 4)) | (plus 2 (times 3 4)) |
| 2 * 3 + 4 |
| 10 | 2 3 * 4 + | + * 2 3 4 | plus(times(2, 3), 4) | (plus (times 2 3) 4) |
| 2 * (3 + 4) |
| 14 | 2 3 4 + * | * 2 + 3 4 | times(2, plus(3, 4)) | (times 2 (plus 3 4)) |
Source and target as text.
Postfix: Stack machine. Easy to write an interpreter.
The "2.5" program from ASU-86:
simple grammar (Sw: "grammatik") (only + and -),
simple parser, very simple scanner (one character = one token).
The "2.9" program from ASU-86:
more advanced grammar (identifiers, *, /, mod, div),
therefore a more complex parser, a "real" scanner.
if (a == b)
printf("Same!\n");
else
printf("Not same!\n");
This, as you know, is the syntax for the if statement:
if ( some expression ) some statement else some other statement
A rule that could be part of a context-free grammar (Sw: kontextfri grammatik) for C:
statement -> if ( expression ) statement else statement
statement -> if ( expression ) statement
statement -> { statement-list } (forgot what?)
...
"Context-free": a production "X -> ..." can always be used to replace X with "...", no matter what the rest of the program (that is, the context, Sw: kontext, omgivning) looks like.
digit -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
list -> digit
list -> list + digit
list -> list - digit
or
digit -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
list -> digit | list + digit | list - digit
Try 9-5+2.
9 -> digit -> list.
5 -> digit.
9-5 -> list - digit -> list
2 -> digit.
9-5+2 -> list + digit -> list
ALSU-87 fig 2.5 = ASU-86 fig 2.2, the parse tree (= concrete syntax tree) and the syntax tree (= abstract syntax tree):
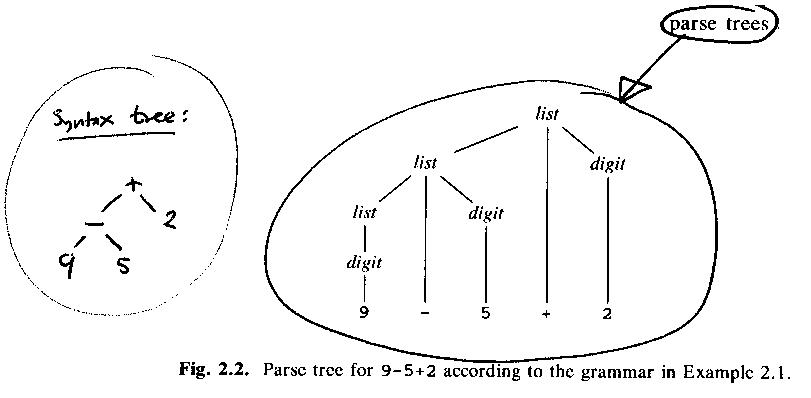
Why list + digit etc? Asymmetrical and ugly? Why not just list + list, like this:
digit -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
string -> digit | string + string | string - string
ALSU-07 fig 2.6 = ASU-86 fig 2.3 (slide!):
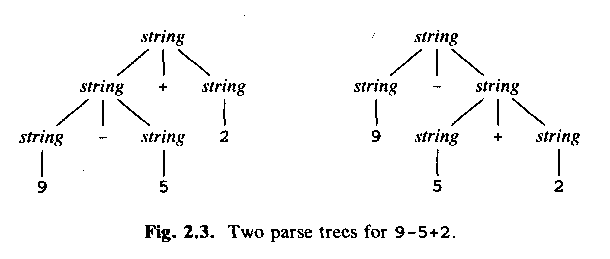
Use a grammar like above, that is,
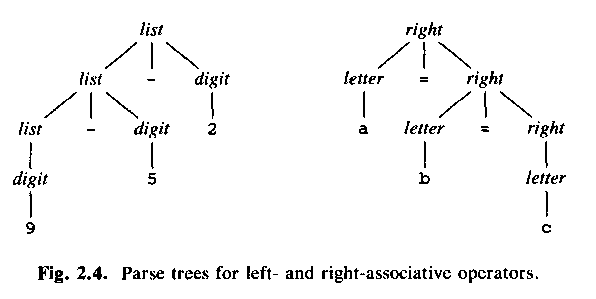
list -> list + digit
for left-associative (Sw: vänsterassociativa) operators.
Use a grammar like
list -> digit + list
for right-associative (Sw: högerassociativa) operators, for example:
right -> letter = right
letter -> a | b | c | ... | z
Express this in the grammar:
factor -> digit | ( expr )
term -> term * factor | term / factor | factor
expr -> expr + term | expr - term | term
Two different types:
Grammar + what to do for each production
Syntax-directed definition = context-free grammar, plus a semantic rule (Sw: semantisk regel) for each production, that specifies how to calculate values of attributes. Example:
| Production | Semantic rule |
|---|---|
| term -> 0 | term.postfixcode -> "0" |
| term -> 1 | term.postfixcode -> "1" |
| term -> 2 | term.postfixcode -> "2" |
| ... | ... |
| expr -> expr1 + term | expr.postfixcode -> expr1.postfixcode + term.postfixcode + " +" |
| ... | ... |
ALSU-07 fig 2.9 = ASU-86 fig 2.6, an annotated (= with attribute values) parse tree:

A syntax-directed definition says nothing about how the parser should build the parse tree! Just the grammar, and what to do when the tree is finished (or at least, when we have found which production to use).
The syntax-directed definition doesn't specifiy in which order the semantic rules should be performed, except of course that he values used in the rules must be available. (For example, expr1.postfixcode and term.postfixcode must be calculated before we can concatenate them into expr.postfixcode.)
Grammar + what to do for each production embedded in the grammar: in the right-hand side of productions
Syntax-directed definition = context-free grammar, plus semantic actions (Sw: semantiska aktioner, semantiska åtgärder) for each production, that specifies what to do. Example:
expr -> expr1 + term { print("+"); }
Generates postfix!
Or, with the action somewhere in the middle:
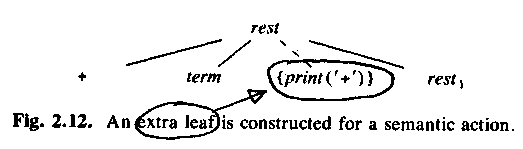
rest -> + term { print("+"); } rest1
The semantic actions are put in the parse tree, just like the "real" parts.
ALSU-07 fig 2.13 =
ASU-86 fig 2.12:
ALSU-07 fig 2.14 = ASU-86 fig 2.14:

As with a syntax-directed definition, a syntax-directed scheme says nothing about how the parser should build the parse tree! Just the grammar, and what to do when the tree is finished.
But we don't actually have to build the tree. Just perform the semantic actions as the tree is (not) built!
In contrast to a syntax-directed definition (which was a table with rules) the semantic actions in a syntax-directed translations scheme must be performed in the right order. They are program segments, such as print statements and variable assignments, and that will of course fail if they are performed in an incorrect order!
The course Compilers and interpreters | Lectures: 1 2 3 4 5 6 7 8 9 10 11 12