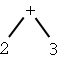
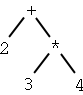
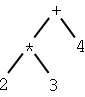
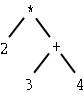
Det här är ungefär vad jag tänker säga på föreläsningen. Använd det för förberedelser, repetition och ledning. Det är inte en definition av kursinnehållet, och det ersätter inte kursboken.
Idag: Mer om syntaktisk analys, "parsning" (engelska: syntactical analysis, parsing)
A compiler that translates infix to postfix:
| Tree | Infix notation | Postfix notation |
|---|---|---|
|
| 2 + 3 | 2 3 + |
|
| 2 + 3 * 4 | 2 3 4 * + |
|
| 2 * 3 + 4 | 2 3 * 4 + |
|
| 2 * (3 + 4) | 2 3 4 + * |
Source and target as text.
Postfix: Stack machine. Easy to write an interpreter.
The "2.5" program from ASU-86:
simple grammar (Sw: "grammatik") (only + and -),
simple parser, very simple scanner (one character = one token).
The "2.9" program from ASU-86:
more advanced grammar (identifiers, *, /, mod, div),
therefore a more complex parser, a "real" scanner.
if (a == b)
printf("Same!\n");
else
printf("Not same!\n");
This, as you know, is the syntax for the if statement:
if ( some expression ) some statement else some other statement
A rule that could be part of a context-free grammar (Sw: kontextfri grammatik) for C:
statement -> if ( expression ) statement else statement
statement -> if ( expression ) statement
statement -> { statement-list } (forgot what?)
...
"Context-free": a production "X -> ..." can always be used to replace X with "...", no matter what the rest of the program (that is, the context, Sw: kontext, omgivning) looks like.
digit -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
list -> digit
list -> list + digit
list -> list - digit
or
digit -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
list -> digit | list + digit | list - digit
Try 9-5+2.
9 -> digit -> list.
5 -> digit.
9-5 -> list - digit -> list
2 -> digit.
9-5+2 -> list + digit -> list
ALSU-87 fig 2.5 = ASU-86 fig 2.2, the parse tree (= concrete syntax tree) and the syntax tree (= abstract syntax tree):
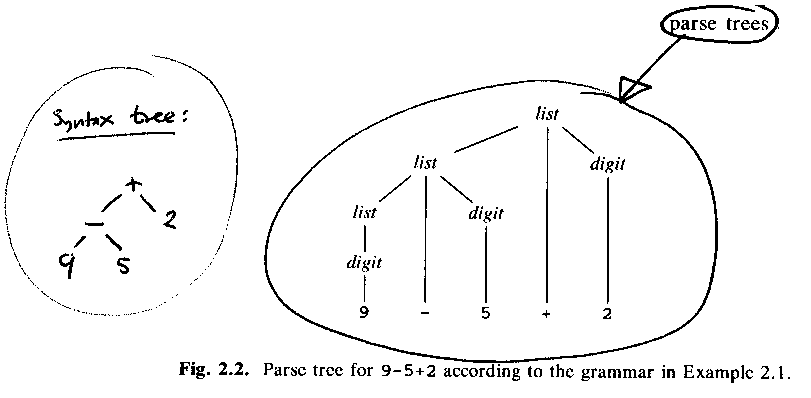
Why list + digit etc? Asymmetrical and ugly? Why not just list + list, like this:
digit -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
string -> digit | string + string | string - string
ALSU-07 fig 2.6 = ASU-86 fig 2.3 (slide!):
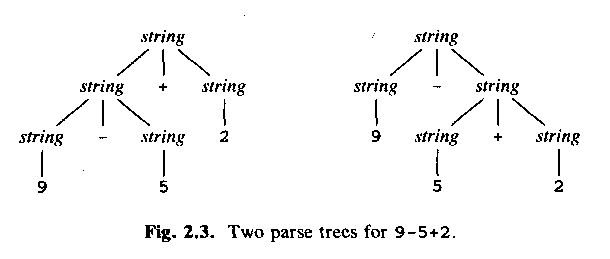
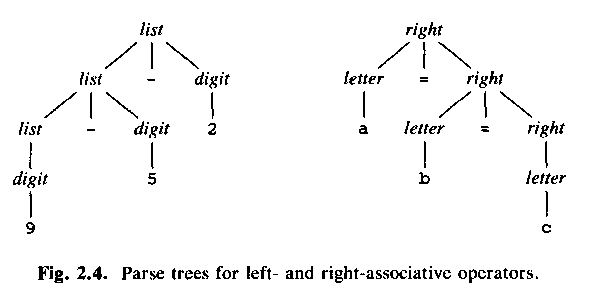
Use a grammar like above, that is,
list -> list + digit
for left-associative (Sw: vänsterassociativa) operators.
Use a grammar like
list -> digit + list
for right-associative (Sw: högerassociativa) operators, for example:
right -> letter = right
letter -> a | b | c | ... | z
Express this in the grammar:
factor -> digit | ( expr )
term -> term * factor | term / factor | factor
expr -> expr + term | expr - term | term
Two different types:
Grammar + what to do for each production
Syntax-directed definition = context-free grammar, plus a semantic rule (Sw: semantisk regel) for each production, that specifies how to calculate values of attributes. Example:
| Production | Semantic rule |
|---|---|
| term -> 0 | term.postfixcode -> "0" |
| term -> 1 | term.postfixcode -> "1" |
| term -> 2 | term.postfixcode -> "2" |
| ... | ... |
| expr -> expr1 + term1 | expr.postfixcode -> expr1.postfixcode + term1.postfixcode + " +" |
| ... | ... |
ALSU-07 fig 2.9 = ASU-86 fig 2.6, an annotated (= with attribute values) parse tree:

A syntax-directed definition says nothing about how the parser should build the parse tree! Just the grammar, and what to do when the tree is finished (or at least, when we have found which production to use).
Den syntax-styrda definitionen säger inte heller något om i vilken ordning de semantisk reglerna ska "köras", förutom förstås att de värden som används i reglerna måste finnas tillgängliga. (Så man måste till exempel räkna ut expr1.postfixcode och term1.postfixcode innan man slår ihop dem till expr.postfixcode.)
Grammar + what to do for each production embedded in the grammar: in the right-hand side of productions
Syntax-directed definition = context-free grammar, plus semantic actions (Sw: semantiska aktioner, semantiska åtgärder) for each production, that specifies what to do. Example:
expr -> expr1 + term1 { print("+"); }
Generates postfix!
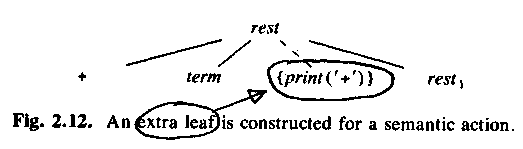
Or, with the action somewhere in the middle:
rest -> + term1 { print("+"); } rest1
The semantic actions are put in the parse tree, just like the "real" parts.
ALSU-07 fig 2.13 =
ASU-86 fig 2.12:
ALSU-07 fig 2.14 = ASU-86 fig 2.14:
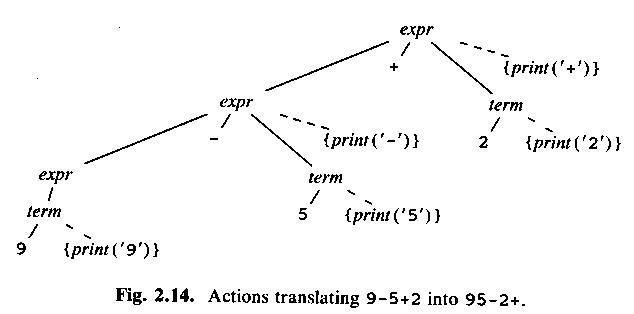
As with a syntax-directed definition, a syntax-directed scheme says nothing about how the parser should build the parse tree! Just the grammar, and what to do when the tree is finished.
But we don't actually have to build the tree. Just perform the semantic actions as the tree is (not) built!
Till skillnad från med en syntax-styrd definition (som var en tabell med regler) så måste de semantiska aktionerna i ett syntax-styrt översättningsschema utföras i rätt ordning. De är programsnuttar (t ex print-satser och variabeltilldelningar), och det blir förstås fel om de görs i fel ordning!
Kursen Kompilatorer och interpretatorer | Föreläsningar: 1 2 3 4 5 6 7 8 9 10 11 12