
| Summary: Due to the physical properties of disks, and to the caching done by the operating system, it is sometimes faster to read a file twice than just read it once. If you read through two files, alternating the reads between them, the read head may have to move back on forth on the disk, causing bad performance. If you start by reading each file sequentially, not doing anything with the contents except just reading it, you pre-load the files into the disk cache, and then the alternating reads will be done from the cache. In one particular case (shown below), the program runs almost twice as fast if it first reads the two input files an extra time. |
What I did was this:
First, check the lengths of the files. Unix has the stat system call, which returns information about a file, including its size in bytes. (I assume that Windows has something similar.) The system keeps this information readily available in the file system, so it is much faster to find the length than to actually open the file and read its contents.
If two files have different length, they can't be equal, so we only need to consider groups of files that have the same length. So the problem now becomes how to compare two or more files of the same length.
One way is to first checksum each file (for example using the MD5 algorithm), and then compare those files that had the same checksum. (Depending on how "cryptographically strong" your checksum algorithm is, you may decide to ignore the compare step, and just accept that two files with the same checksum probably are equal.)
In any case, checksumming a file requires that you read through it. If two files (of the same length) differ in the very first byte, we still have to read through each of them in order to calculate the checksums.
Another way to compare the files is to open them and read them in parallel, comparing each byte (or larger block). You can then stop reading as soon as you find a difference, and this will improve the performance. (Or so I thought, at the time.) It is simple to do this for two files, but it can also be done for three or more files, and I actually implemented a version of my duplicate-finding program that opened up to a thousand files and read them in parallell. (Operating systems usually have a limit on the number of files that a process can have open at the same time, and the limit in the Linux I was using was 1024.)
Here is a normal physical disk drive (even if this model is a bit old). Note the elegantly drawn disk blocks along a track.
We all know that fragmentation is bad. The best way to store a file on the disk is with the data sequentially along one or more tracks. The read head can then just follow the track, and read all the data without moving:

Compare this to a heavily fragmented disk, where, the data for a file is spread on several tracks, with one block here and one block there. To read the file, we have to move the read head between the tracks:
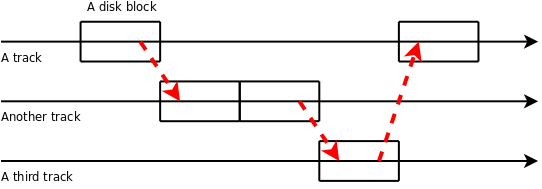
Moving the read head is very slow compared to keeping it still (and of course ridiculosoly slow compared to the data processing done electronically by the CPU). This is why fragmentation is bad.
Now, we have two (unfragmented) files:
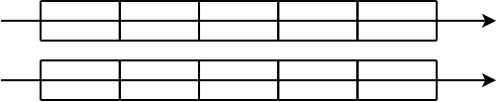
If we read first one file from start to end, and then the other, they can be read sequentially. But if we open both files at the same time, and then alternate between them when reading, we have to move the read head back and forth between the tracks:
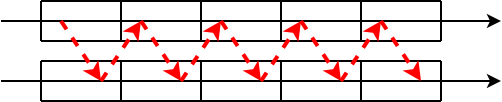
Because of this, it is usually faster to read two files one after the other, instead of in parallel.
Now we add caching. Many operating system have a disk cache. If a program wants data from a file, the operating system reads the data from the disk and sends it to the program, but the operating system also stores the data in a cache in main memory. If another program (or the same one) wants the same data later on, it doesn't have to be read from the disk again, but can be retrieved from the cache in main memory. This is good, since main memory is about a million times or so faster than the disk. Look at the following example from my Linux computer:
wc is a small Unix program that counts the number of lines, words and characters in a file. time is a command that shows the execution time, and some other resource usages, of a program. jdk-6u10-linux-i586.bin is just a moderately large file that I happened to have available.> time wc jdk-6u10-linux-i586.bin 308009 1775135 80009636 jdk-6u10-linux-i586.bin 1.540u 0.100s 0:02.80 58.5% 0+0k 156848+0io 4pf+0w > time wc jdk-6u10-linux-i586.bin 308009 1775135 80009636 jdk-6u10-linux-i586.bin 1.548u 0.080s 0:01.62 100.0% 0+0k 0+0io 0pf+0w > time wc jdk-6u10-linux-i586.bin 308009 1775135 80009636 jdk-6u10-linux-i586.bin 1.572u 0.060s 0:01.63 100.0% 0+0k 0+0io 0pf+0w > flush-cache Flushing page cache, dentries and inodes... Done flushing. > time wc jdk-6u10-linux-i586.bin 308009 1775135 80009636 jdk-6u10-linux-i586.bin 1.544u 0.124s 0:02.78 59.7% 0+0k 156816+0io 4pf+0w
Look at the numbers in red. The first time I ran wc, it took 2.80 seconds. The second time I ran the exact same command, it was a bit faster, 1.62 seconds. This is beacause now the content of the file is cached in main memory, and doesn't have to be read from the disk. We can also see, from the statistics printed by the time command, that the first run used 156848 I/O operations, and the second one zero.
The third run of the same program was also fast, with the file still in cache. Then I used the flush-cache program (source flush-cache.c) to flush the disk cache, and then, when running the wc command for the fourth time, it is slower again, having to access the disk drive.
Now, back to the two files that we should read from disk. We want to compare them. Here are two programs:
I also made two versions of the programs which explicitly read 4096-byte blocks, using the read system call, instead of using getc from the stdio library, just to be sure that stdio wasn't doing anything funny:
These blockwise programs show similar performance to the bytewise programs.
And then there are two versions of the programs with a much larger block size. These two programs read 1-megabyte blocks:
For completeness I also tried these:Test results:
| Program | Average time |
|---|---|
| simple-compare | 17.72 |
| compare-with-extra-read | 9.64 |
| block-compare-4k | 17.38 |
| block-compare-with-extra-read-4k | 6.17 |
| block-compare-1M | 7.48 |
| block-compare-with-extra-read-1M | 6.24 |
| unlocked-compare | 17.50 |
| block-compare-100M | 6.19 |
Some conclusions:
The interesting part is comparing simple-compare (17.72 seconds) and compare-with-extra-read (9.64 seconds). As we can see, it is faster to read the files an extra time to load them into disk cache.
The "4k block, non-stdio" versions of the programs show similar performance, so the effect of cache pre-loading is not in some strange way caused by the stdio library. (An anomaly is that block-compare-with-extra-read-4k has much better performance than compare-with-extra-read. I don't know the reason for that.)
By reading the files in larger chunks, disk access is more sequential, and there is less effect from cache pre-loading.
Finally, in this case, there was no difference between the thread-safe and thread-unsafe versions of stdio (getc and getc_unlocked).
Of course, with files that actually are different, especially in the beginning, the extra reads will be much slower. But for (large) files that are equal, or differ only at the end, it is faster to first read them an extra time, before comparing them to each other.
The above tests were run in 2009, using a mechanical disk. In 2016 there are much faster solid-state devices, SSDs, and also mechanical disks that are faster than what was available in 2009. I re-ran the tests, with an SSD and also with a faster mechanical disk. I used a computer with a Core i7 6850K 3.6 GHz processor, 128 GB of 2133 MHz DDR4 memory, a Samsung 950 Pro M.2 SSD, and a HGST Ultrastar 7K4000 mechanical disk. The source code for block-compare-100M was missing, so that test was not run.
Results:
| Program | HDD 2009 | SSD 2016 | HDD 2016 |
|---|---|---|---|
| simple-compare | 17.72 | 1.12 | 1.86 |
| compare-with-extra-read | 9.64 | 2.21 | 2.53 |
| block-compare-4k | 17.38 | 0.10 | 2.81 |
| block-compare-with-extra-read-4k | 6.17 | 0.13 | 1.45 |
| block-compare-1M | 7.48 | 0.16 | 2.34 |
| block-compare-with-extra-read-1M | 6.24 | 0.16 | 1.47 |
| unlocked-compare | 17.50 | 0.49 | 2.76 |
| block-compare-100M | 6.19 |
When reading from an SSD, the surprising effects have disappeared. In the 2009 tests with a mechanical disk, reading from the disk dominated the execution times. In these new tests with an SSD, reading from the device is no longer dominant, and caching is no longer as important as it was. Data processing after the file has been read now seems to dominate the execution times. Reading the files twice compared to once, as in compare-with-extra-read compared to simple-compare, takes almost exactly twice the time, just as would be naively expected. Reading using functions from the stdio library is slow, compared to using the lower-level read function.
The mechanical hard disk from 2016 is several times faster than the disk from 2009. The disk is so fast that data processing in memory is important, and we need to minimize that processing by using the low-level read function. When we do that, we find that reading the file twice can be faster, just as in 2009, as in block-compare-with-extra-read-4k compared to block-compare-4k.