{kind=link}

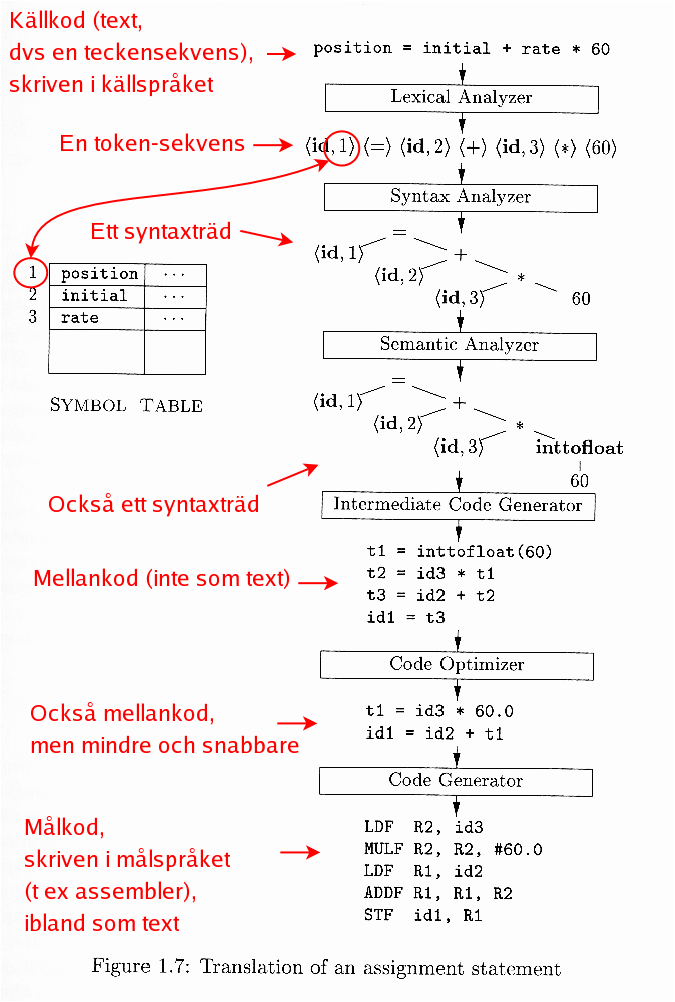
Se också boken eller föreläsningsanteckningarna, särskilt den här figurern, med tillägget att den maskinberoende optimeringen ger som utdata målkod i målspråket, men mindre och snabbare jämfört med den kod som är utdata från kodgeneratorn.
a = b;
c = 17;
while (x < 19) {
x = x + b - c - 1;
if (c > 0)
c = c - 1;
r = r + 2 * b;
}
|
Översätt ovanstående programavsnitt till två av följande tre typer av mellankod.
a) ett abstrakt syntaxträd (genom att rita upp trädet!)
b) postfixkod för en stackmaskin
lvalue a
rvalue b
assign
lvalue c
push 17
assign
label 1:
rvalue x
push 19
lt
gofalse 2
lvalue x
rvalue x
rvalue b
plus
rvalue c
minus
push 1
minus
assign
rvalue c
push 0
le
gofalse 3
lvalue c
rvalue c
push 1
minus
assign
label 3:
lvalue r
rvalue r
push 2
rvalue b
times
plus
assign
jump 1
label 2:
c) treadresskod
a = b
c = 17
label 1:
if (x >= 19) goto 2
temp1 = x + b
temp2 = temp1 - c
x = temp2 - 1
if (c <= 0) goto 3
c = c - 1
label 3:
temp3 = 2 * b;
r = r + temp3
goto 1
label 2:
Man kan också använda temporärvariabler för varje deluttryck, så att exempelvis "x = temp2 - 1" ovan i stället blir "temp3 = temp2 - 1; x = temp3".
kommandolista -> kommando kommandolista | *tomt* kommando -> anslagskommando | anslagstavlekommando | placeringskommando anslagskommando -> skapa anslag heltal rubrik innehåll rubrik -> textsträng innehåll -> textsträng anslagstavlekommando -> skapa anslagstavla heltal placeringskommando -> sätt upp anslag heltal på anslagstavla heltal
Här är också en Flex-fil som beskriver hur terminalerna i språket ser ut:
%{
#include "anslag.tab.h"
%}
%%
[\n\t ] { /* Ignorera whitespace */ }
skapa { return skapa; }
anslag { return anslag; }
anslagstavla { return anslagstavla; }
sätt { return sätt; }
upp { return upp; }
på { return på; }
[0-9]+ { return heltal; }
\"[^"]*\" { return textsträng; }
. { fprintf(stderr, "Ignorerar felaktigt tecken: '%c'\n", *yytext); }
%%
a) Icke-terminalen kommando beskriver de kommandon som man kan ge. Ange fem olika kommandon som ingår i det språk som beskrivs av grammatiken ovan. Variera dem så att de inte är alltför lika.
skapa anslag 13 "Säljes" "En båt" skapa anslag 13 "Köpes" "En väldigt fin liten båt som jag kan segla med" skapa anslagstavla 14 sätt upp anslag 13 på anslagstavla 14 sätt upp anslag 14 på anslagstavla 17
b) Ange fem olika kommandon som inte ingår i det språk som beskrivs av grammatiken ovan, men som man kanske skulle kunna tro gjorde det om man inte var så bra på grammatiker och Flex.
kommando kommandolista skapa anslag heltal rubrik innehåll sätt upp anslag heltal på anslagstavla heltal *tomt* skapa anslagstavla [0-9]+
c) Den här grammatiken lämpar sig inte för implementation av en prediktiv recursive-descent-parser. Ange vilket eller vilka problem som finns, vad i grammatiken som orsakar problemen, och vad som händer i parsern.
Vi har en FIRST()-konflikt eftersom både anslagskommando och anslagstavlekommando börjar med terminalen skapa. Om vi ska parsa ett kommando och hittar terminalen skapa i inmatningen, vet vi därför inte om det som kommer är ett anslagskommando eller ett anslagstavlekommando. Proceduren kommando i parsern skulle se ut så här:
void kommando() {
if (lookahead == SÄTT)
placeringskommando();
else if (lookahead == SKAPA)
// Ja, vad? Ska vi anropa anslagskommando eller anslagstavlekommando?
d) Använd de transformationer som tagits upp i kursen för att omvandla grammatiken till en grammatik som beskriver samma språk, men som enkelt kan implementeras i en prediktiv recursive-descent-parser. Ange vilka transformationer du gör, och visa vad resultatet blir för den här grammatiken.
Väsnterfaktorisering ger:
kommandolista -> kommando kommandolista | *tomt* kommando -> skapa skapelse | placeringskommando skapelse -> anslagsskapelse | anslagstavleskapelse anslagsskapelse -> anslag heltal rubrik innehåll rubrik -> textsträng innehåll -> textsträng anslagstavleskapelse -> anslagstavla heltal placeringskommando -> sätt upp anslag heltal på anslagstavla heltal
e) Skriv den prediktiva recursive-descent-parsern i ett språk som åtminstone liknar C, Java eller Pascal. Du behöver inte skriva exakt korrekt programkod, men det ska framgå vilka procedurer som finns, hur de anropar varandra, och vilka jämförelser med tokentyper som görs. Du kan anta att det finns en funktion som heter scan, och att den returnerar typen på nästa token.
Ladda ner och provkör: anslagsparser.c
int lookahead;
void error() {
printf("Det har tyvärr uppstått ett fel.\n");
exit(EXIT_FAILURE);
}
void match(int expected) {
if (lookahead != expected)
error();
else
lookahead = scan();
}
void kommandolista(void) {
if (lookahead == SKAPA || lookahead == SATT) {
kommando(); kommandolista();
}
else {
// Tomt
}
}
void kommando(void) {
if (lookahead == SKAPA) {
match(SKAPA); skapelse();
}
else if (lookahead == SATT) {
placeringskommando();
}
else {
error();
}
}
void skapelse(void) {
if (lookahead == ANSLAG) {
anslagsskapelse();
}
else if (lookahead == ANSLAGSTAVLA) {
anslagstavleskapelse();
}
else {
error();
}
}
void anslagsskapelse(void) {
match(ANSLAG); match(HELTAL); rubrik(); innehall();
}
void rubrik(void) {
match(TEXTSTRANG);
}
void innehall(void) {
match(TEXTSTRANG);
}
void anslagstavleskapelse(void) {
match(ANSLAGSTAVLA); match(HELTAL);
}
void placeringskommando(void) {
match(SATT); match(UPP); match(ANSLAG); match(HELTAL); match(PA); match(ANSLAGSTAVLA); match(HELTAL);
}
void parse() {
lookahead = scan();
kommandolista();
printf("Ok.\n");
}

b)
Rotmängden är utgångspunkten för vad som är nåbart från programmet.
Dataobjekt som finns i rotmängden, eller som kan nås via pekare i ett eller flera steg från objekt i rotmängden,
är nåbara, och eftersom de är nåbara kan det hända att vi kommer att använda dem i framtiden, så de ska inte förstöras.
Ej nåbara objekt kan inte nås, och kommer därför inte att användas, så de kan förstöras.
c)
Objekt 1: 2
Objekt 2: 1
Objekt 3: 1
Objekt 4: 2
Objekt 5: 2
Objekt 6: 1
Objekt 7: 1
Objekt 8: 1