{kind=link}
 syntax tree")
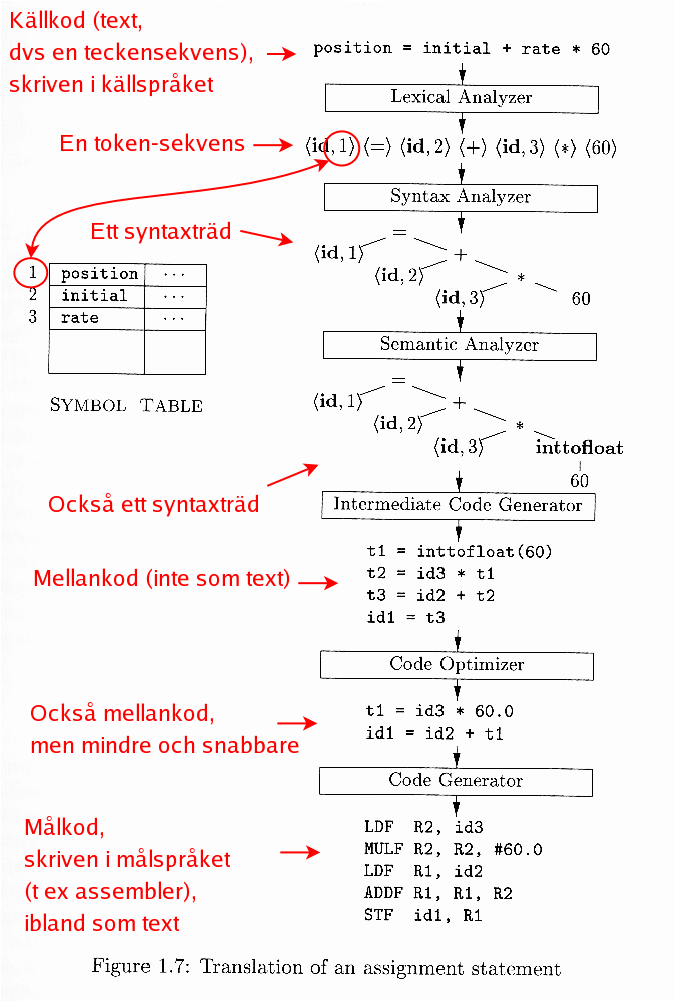
See also the book or the lecture notes, especially this figure, with the addition of the machine-dependent optimizer.
#include <stdio.h>
int main(void) {
prontf("Starting...\n"); // 1: undefined reference to `prontf'
int a = 17zzz; // 2: invalid suffix on integer constant
int b = ; // 3: expected expression before ';' token
int c = 0;
if (c == 0) {
int d = a / c; // 4: math exception
int e, f, g;
int h // 5: expected '=', ',' or ';' before 'e'
e = 17; // 6: variable 'e' set but not used
f = g; // 7: 'g' may be used uninitialized
printf("d = %d, f = %d\n", d, f);
}
return "Done!"; // 8: return makes integer from pointer
}
x = 0;
y = z * 2 - t - 2 * 2;
while (x < y) {
if (x < 5) {
x = x + 1;
}
else {
x = x + 2;
y = y + 1;
}
}
a) Translate the program segment to an abstract syntax tree (by drawing it).
b) Translate the program segment to either postfix code for a stack machine or three-address code. (Not both!)
Postfix code for a stack machine:
lvalue x
push 0
=
lvalue y
rvalue z
push 2
*
rvalue t
-
push 2
push 2
*
-
=
label WHILE-START:
rvalue x
rvalue y
<
gofalse AFTER-WHILE
rvalue x
push 5
<
gofalse ELSE-START
lvalue x
rvalue x
push 1
+
=
goto AFTER-IF
label ELSE-START:
lvalue x
rvalue x
push 2
+
=
lvalue y
rvalue y
push 1
+
=
label AFTER-IF:
goto WHILE-START
label AFTER-WHILE:
Three-address code:
x = 0
temp1 = z * 2
temp2 = temp1 - t
temp3 = 2 * 2
y = temp2 - temp3
label WHILE-START:
if (x >= y) goto AFTER-WHILE
if (x >= 5) goto ELSE-START
x = x + 1
goto AFTER-IF
label ELSE-START:
x = x + 2
y = y + 1
label AFTER-IF:
goto WHILE-START
label AFTER-WHILE:
Or, if we number the instructions and use those numbers instead of labels:
(1) x = 0 (2) temp1 = z * 2 (3) temp2 = temp1 - t (4) temp3 = 2 * 2 (5) y = temp2 - temp3 (6) if (x >= y) goto 13 (7) if (x >= 5) goto 10 (8) x = x + 1 (9) goto 12 (10) x = x + 2 (11) y = y + 1 (12) goto 6 (13)
Name (of a species), number (of observed animals), and the keywords species, declarations, done, observation and observations.
b) (2p) Out of the terminals, some will not have fixed lexemes. Write regular expressions for each such terminal.
input -> manydeclarations declarations done manyobservations observations done
manydeclarations -> onedeclaration manydeclarations | ε
onedeclaration -> species name
manyobservations -> oneobservation manyobservations | ε
oneobservation -> observation name number
Download: animalsparser.c, plus a Lex-scannerspecifikation animals.l, and a Bison version of the grammar animals.y, and a Makefile.
Since the grammar from the solution to the task above is already suitable for constructing a predictive recursive-descent parser, we can use it directly. Otherwise, we would have had to make some transformations.
int lookahead;
void match(int expected) {
if (lookahead != expected)
error();
else
lookahead = scan();
}
void input(void) {
manydeclarations(); match(DECLARATIONS); match(DONE); manyobservations(); match(OBSERVATIONS); match(DONE);
}
void manydeclarations(void) {
if (lookahead == SPECIES) {
onedeclaration(); manydeclarations();
}
else {
/* Empty */
}
}
void onedeclaration(void) {
match(SPECIES); match(NAME);
}
void manyobservations(void) {
if (lookahead == OBSERVATION) {
oneobservation(); manyobservations();
}
else {
/* Empty */
}
}
void oneobservation(void) {
match(OBSERVATION); match(NAME); match(NUMBER);
}
void parse() {
lookahead = scan();
input();
printf("Ok.\n");
}