
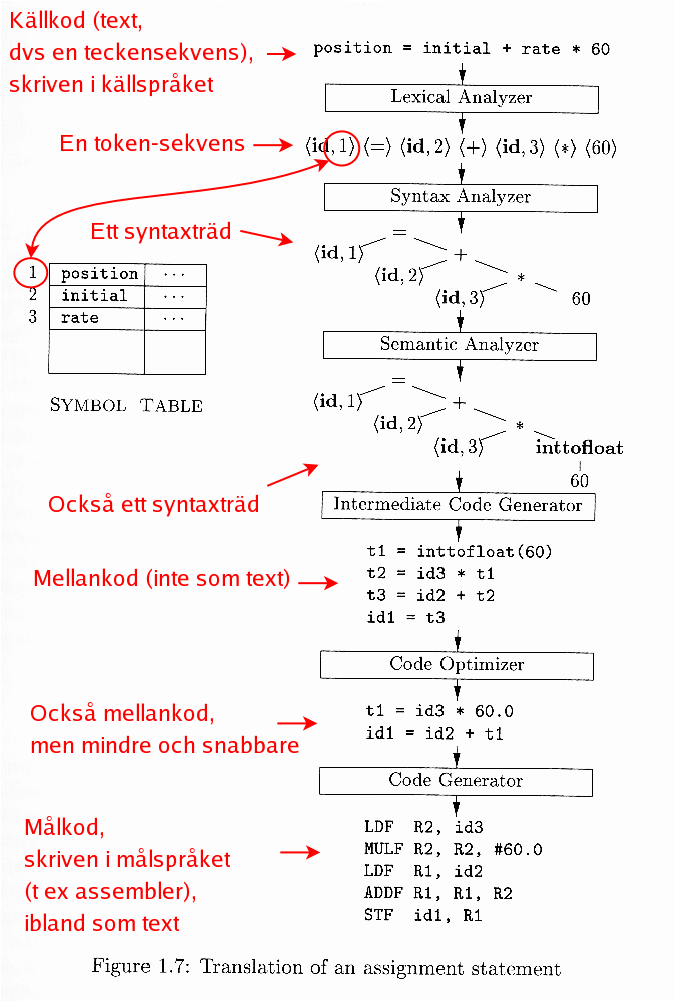
Se också boken eller föreläsningsanteckningarna, särskilt den här figuren, med tillägget att den maskinberoende optimeringen ger som utdata målkod i målspråket, men mindre och snabbare jämfört med den kod som är utdata från kodgeneratorn.
#include <stdi.h> // fatal error: stdi.h: No such file or directory preprocessorn
int main(void) {
double d1 = 1.0; // warning: unused variable 'd1' maskinoberoende optimering eller kanske semantisk analys
int d1 = 2; // error: conflicting types for 'd1' semantisk analys
double 2; // error: expected identifier or '(' before numeric constant parser
int i = 17;
printf(Hej!); // error: 'Hej' undeclared semantisk analys
// error: expected ')' before '!' token parser
printg("%d", i); // undefined reference to `printg' länkning
printf("%s", i); // Segmentation fault (core dumped) exekvering
return 0;
}
#include <stdlib.h>
#include <stdio.h>
int a = 1, b = 2;
int f(int x, int y) {
int c;
int *d;
a = x;
c = 3;
d = malloc(sizeof(int));
*d = b;
if (x < 2) {
return x * f(x + 1, y + 2);
}
else {
printf("Nu!\n");
return 1;
}
}
int main(void) {
int a;
int *b;
a = 2;
b = malloc(sizeof(int));
*b = 3;
a = f(0, 4);
return 0;
}
a = 1;
b = c * 2 + 3 + d;
if (a < b) {
while (a + 4 < b * 5 + c) {
a = a + 6;
}
}
else {
a = 7;
b = 8;
}
Översätt ovanstående programavsnitt till
två av följande tre typer av mellankod.
a) ett syntaxträd, även kallat abstrakt syntaxträd (genom att rita upp trädet!)
 syntaxträd")
En kommentar: Man kan avsluta ";-listorna" med NULL i stället för den sista satsen i listan. Det blir lite mer att rita, men kan vara lite enklare programmeringsmässigt.
b) postfixkod för en stackmaskin
lvalue a
push 1
=
lvalue b
rvalue c
push 2
*
push 3
+
rvalue d
+
=
rvalue a
rvalue b
lt
gofalse ELSE-START
label WHILE-START:
rvalue a
push 4
+
rvalue b
push 5
*
rvalue c
+
lt
gofalse AFTER-WHILE
lvalue a
rvalue a
push 6
+
=
goto WHILE-START
label AFTER-WHILE:
goto AFTER-IF
label ELSE-START:
lvalue a
push 7
=
lvalue b
push 8
=
label AFTER-IF:
En kommentar: Exemplen i kursen har oftast använt numeriska programlägesetiketter ("labels"), men man kan som ovan ha en stackmaskin som förstår mnemoniska namn. Det blir lite lättare att läsa. Har man flera if-satser eller while-loopar måste man förstås generera namn som är olika, till exempel ELSE-START-1, ELSE-START-2 och så vidare.
c) treadresskod
a = 1
temp1 = c * 2
temp2 = temp1 + 3
temp3 = temp2 + d
b = temp3
if a ≥ b goto ELSE-START
label WHILE-START:
temp4 = a + 4
temp5 = b * 5
temp6 = temp5 + c
if temp4 ≥ temp6 goto AFTER-WHILE
temp7 = a + 6
a = temp7
goto WHILE-START
label AFTER-WHILE:
goto AFTER-IF
label ELSE-START:
a = 7
b = 8
label AFTER-IF:
En kommentar: Man kan redan här optimera bort (eller snarare låta bli att generera) temporärvariabler i tilldelningar, så de två instruktionerna "temp3 = temp2 + d" och "b = temp3" ovan i stället blir "b = temp2 + d".
En beställning börjar med nyckelordet start och avslutas med nyckelordet klart. Efter nyckelordet start kommer nyckelordet namn följt av en textsträng som anger namnet på kunden. Därefter kan det, men måste inte, komma nyckelordet telefon följt av en textsträng som anger telefonnumret till kunden. Efter detta en eller flera fikabrödsbeställningar, där var och en består av ett tal (som kan innehålla decimaler) och ett av orden kanelbulle, wienerbröd och chokladboll. Blanktecken, som mellanslag och radslut, ska ignoreras, förutom inuti nyckelord, tal och textsträngar.
Här följer två exempel på beställningar:
start namn "Anna A. Andersson" telefon "070-73 47 013" 1 kanelbulle 2 wienerbröd 1 kanelbulle 1 chokladboll 3 chokladboll klart |
start namn
"Anna A. Andersson" 1
kanelbulle 2 wienerbröd
klart
|
Nyckelorden start, klart, namn, telefon, kanelbulle, wienerbröd och chokladboll, samt tal och sträng.
beställning -> start namndel telefondel lista klart
namndel -> namn sträng
telefondel -> telefon sträng | ingenting
lista -> sak | sak lista
sak -> tal fikatyp
fikatyp -> kanelbulle | wienerbröd | chokladboll
ingenting står för en tom produktion, och brukar oftast skrivas med en liten "e"-symbol, som tyvärr inte verkar fungera överallt i HTML.
start namn "Olle" 1 kanelbulle 2 wienerbröd klart |
Eftersom det finns en FIRST()-konflikt i de två produktionerna lista -> sak | sak lista måste vi vänsterfaktorisera, vilket ger en ny grammatik:
beställning -> start namndel telefondel lista klart
namndel -> namn sträng
telefondel -> telefon sträng | ingenting
lista -> sak flersaker
flersaker -> lista | ingenting
sak -> tal fikatyp
fikatyp -> kanelbulle | wienerbröd | chokladboll
Ladda ner: fikaparser.c, plus en hjälpfil i form av en Lex-scannerspecifikation fika.l.
void match(int expected) {
if (lookahead != expected)
error();
else
lookahead = scan();
}
void beställning(void) {
match(start); namndel(); telefondel(); lista(); match(klart);
}
void namndel(void) {
match(namn); match(sträng);
}
void telefondel(void) {
if (lookahead == telefon) {
match(telefon); match(sträng);
}
else {
/* empty */
}
}
void lista(void) {
sak(); flersaker();
}
void flersaker(void) {
if (lookahead == tal) {
lista();
}
else {
/* empty */
}
}
void sak(void) {
match(tal); fikatyp();
}
void fikatyp(void) {
if (lookahead == kanelbulle) {
match(kanelbulle);
}
else if (lookahead == wienerbröd) {
match(wienerbröd);
}
else if (lookahead == chokladboll) {
match(chokladboll);
}
else
error();
}
void parse() {
lookahead = scan();
beställning();
printf("Ok.\n");
}

{kind=link}