 syntaxträd")
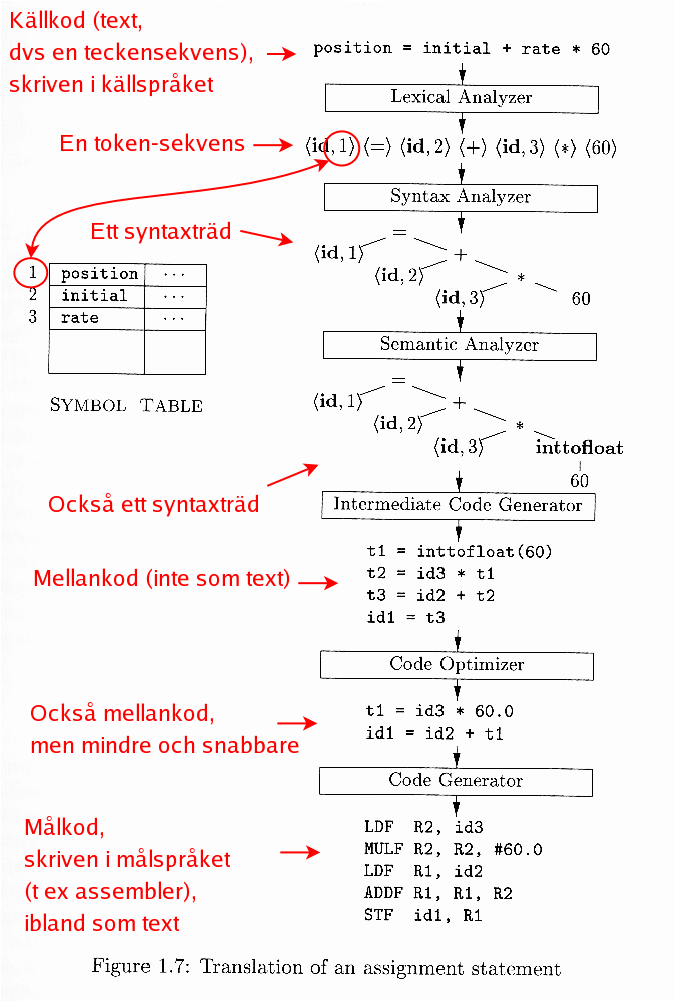
Se också boken eller föreläsningsanteckningarna, särskilt den här figurern, med tillägget att den maskinberoende optimeringen ger som utdata målkod i målspråket, men mindre och snabbare jämfört med den kod som är utdata från kodgeneratorn.
if (a < b)
c = a;
else
c = b;
while (a < b) {
a = a * 2 + 3 * d;
b = b - d - 1;
}
Översätt ovanstående programavsnitt till var och en av följande tre typer av mellankod.
a) ett syntaxträd, även kallat abstrakt syntaxträd (genom att rita upp trädet!)
b) postfixkod för en stackmaskin
rvalue a
rvalue b
lt
gofalse 1
lvalue c
rvalue a
assign
goto 2
label 1:
lvalue c
rvalue b
assign
label 2:
label 3:
rvalue a
rvalue b
lt
gofalse 4
lvalue a
rvalue a
push 2
*
push 3
rvalue d
*
+
assign
lvalue b
rvalue b
rvalue d
-
push 1
-
assign
goto 3
label 4:
c) treadresskod
if (a ≥ b) goto 1
c = a
goto 2
label 1:
c = b
label 2:
label 3:
if a ≥ b goto 4
t1 = a * 2
t2 = 3 * d
t3 = t1 + t2
a = t3
t4 = b - d
t5 = t4 - 1
b = t5
goto 3
label 4:
Man kan redan här optimera bort (eller snarare låta bli att generera) temporärvariabler i tilldelningar, så att exempelvis de två instruktionerna "t3 = t1 + t2" och "a = t3" ovan i stället blir "a = t1 + t2".
struct Punkt {
int nummer;
float x, y;
};
I de förenklade struct-deklarationer som vårt program ska klara
finns bara de två datatyperna int och float.
Här är ett annat exempel på en struct-deklaration, som visar att C-kod kan skrivas på fritt format, dvs att man kan stoppa in extra mellanslag och radbrytningstecken:
struct Banan { float pris;
float vikt;
int
banannummer;
float pos1, pos2, pos3, pos3b; };
Vänsterklammer ({), högerklammer (}), kommatecken (,), semikolon (;), namn/identifierare, samt nyckelorden struct, int och float.
b) Ange reguljära uttryck för de terminaler som inte har ett fast utseende.
namn/identifierare: [A-Za-z_][A-Za-z_0-9]*
deklaration -> struct namn { medlemmar } ;
medlemmar -> medlem medlemmar | medlem
medlem -> datatyp variabler ;
datatyp -> int | float
variabler -> namn , variabler | namn
Egentligen kan en struct vara helt tom i C, men för att uppgift 8 ska bli roligare har jag gjort grammatiken så att en struct måste ha minst en medlemsvariabel.
struct Vara {
int nummer;
float pris, vikt;
};
Det finns FIRST()-konflikter i produktionerna för medlemmar och i produktionerna för variabler, så grammatiken måste först skrivas om med hjälp av två vänsterfaktoriseringar:
deklaration -> struct namn { medlemmar } ;
medlemmar -> medlem fler-medlemmar
fler-medlemmar -> medlemmar | ingenting
medlem -> datatyp variabler ;
datatyp -> int | float
variabler -> namn fler-variabler
fler-variabler -> , variabler | ingenting
ingenting står för en tom produktion.
Ladda ner: structparser.c, plus en hjälpfil i form av en Lex-scannerspecifikation struct.l
#include <stdlib.h>
#include <stdio.h>
#include "struct.tab.h" // Bara för att få tokenkoderna
// Från Bison: %token STRUCT INT FLOAT NAMN
extern int yylex(void);
int lookahead;
int scan(void) {
return yylex();
}
void error() {
printf("Det har tyvärr uppstått ett fel.\n");
exit(EXIT_FAILURE);
}
void match(int expected) {
if (lookahead != expected)
error();
else
lookahead = scan();
}
void deklaration(void),
medlemmar(void),
fler_medlemmar(void),
medlem(void),
datatyp(void),
variabler(void),
fler_variabler(void);
void deklaration(void) {
match(STRUCT); match(NAMN); match('{'); medlemmar(); match('}'); match(';');
}
void medlemmar(void) {
medlem(); fler_medlemmar();
}
void fler_medlemmar(void) {
if (lookahead == INT || lookahead == FLOAT)
medlemmar();
else
; /* Ingenting */
}
void medlem(void) {
datatyp(); variabler(); match(';');
}
void datatyp(void) {
if (lookahead == INT)
match(INT);
else if (lookahead == FLOAT)
match(FLOAT);
else
error();
}
void variabler(void) {
match(NAMN); fler_variabler();
}
void fler_variabler(void) {
if (lookahead == ',') {
match(','); variabler();
}
else {
/* Ingenting */
}
}
void parse() {
lookahead = scan();
deklaration();
printf("Ok.\n");
}
int main() {
printf("Mata in kommandon. Avsluta med KLART-kommandot och EOF.\n");
parse();
}
// Behövs för Lex
int yywrap(void) {
return 1;
}


{kind=link}