
Förslag på lösning:
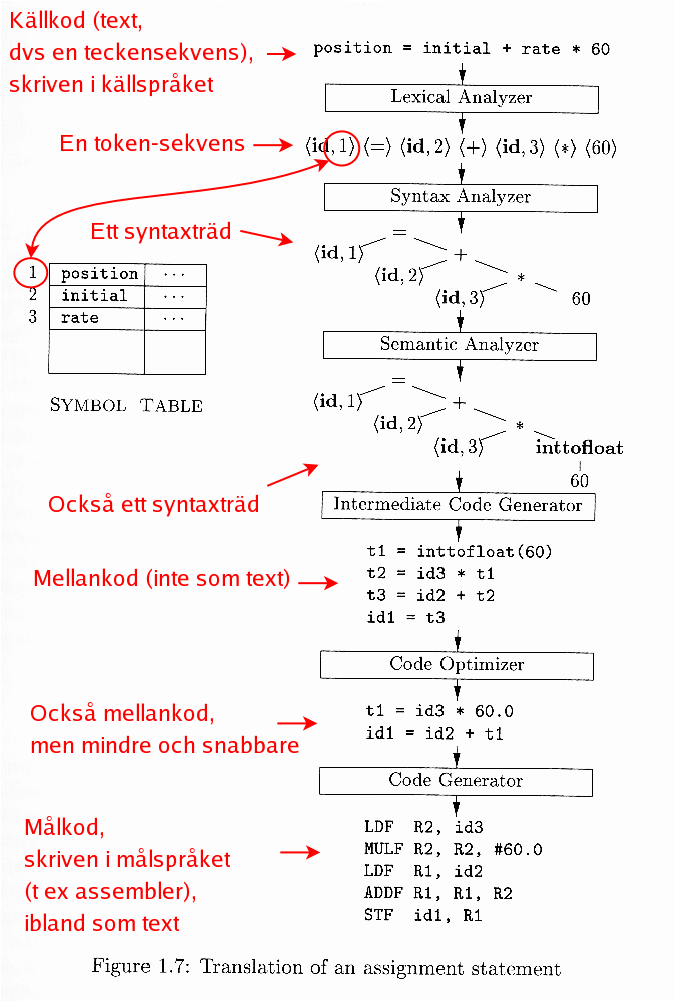
Se också boken eller föreläsningsanteckningarna, särskilt den här figurern, med tillägget att den maskinberoende optimeringen ger som utdata målkod i målspråket, men mindre och snabbare jämfört med den kod som är utdata från kodgeneratorn.
Förslag på lösning:
x = y;
z = 0;
while (z < y - 2) {
x = x + y - 1;
x = z - (x - 2);
}
Översätt ovanstående programavsnitt till var och en av följande tre typer av mellankod.
a) ett abstrakt syntaxträd (genom att rita upp trädet!)
Förslag på lösning:
b) postfixkod för en stackmaskin
Förslag på lösning:
lvalue x
rvalue y
assign
lvalue z
push 0
assign
label 1:
rvalue z
rvalue y
push 2
minus
lt
gofalse 2
lvalue x
rvalue x
rvalue y
plus
push 1
minus
assign
lvalue x
rvalue z
rvalue x
push 2
minus
minus
assign
jump 1
label 2:
c) treadresskod
Förslag på lösning:
x = y
z = 0
label 1:
temp1 = y - 2
if z ≥ temp1 goto 2
temp2 = x + y
x = temp2 - 1
temp3 = x - 2
x = z - temp3
goto 1
label 2:
Man kan också använda temporärvariabler för varje deluttryck, så att exempelvis "x = temp2 - 1" ovan i stället blir "temp3 = temp2 - 1; x = temp3".
Skulle någon eller några faser av kompilatorn kunna påverkas av att loopen är oändlig? Vilka i så fall, och hur påverkas de?
Förslag på lösning:
Det kan påverka (den maskinoberoende) optimeraren (och därigenom faser efter denna). Om värdet på y alltid är sådant att loopvillkoret blir sant, och optimeraren kan bevisa detta, och den också kan bevisa att loopen då blir oändlig, skulle den kunna göra optimeringar baserat på det. Om programmet aldrig lämnar loopen, kommer det inte att använda några beräknade värden. (Givet att koden i loopen inte har några sidoeffekter, och inget som kan påverka en parallell tråd.) Kanske kan optimeraren ersätta hela programmetavsnittet med kod motsvarande den här källkoden:
while (true) {
/* Ingenting */
}
Eller kanske en halt-instruktion till processorn.
Det har funnits C-optimerare som helt tar bort oändliga loopar som inte gör något i loopkroppen. Det är oklart om det är tillåtet enligt C-standarden.
Kommentar: Det är inte ett orimligt svar att faserna inte påverkas alls. Beroende på hur koden före det givna avsnittet ser ut, kan det mycket väl vara så att villkoret inte alls alltid är sant, eller att det är svårt eller omöjligt för optimeraren att bevisa detta. Kanske gör just den här optimeraren inte den här typen av optimering.
#include <stdio.h>
int alpha = 1;
int bravo(void) {
alpha = 10;
printf("Här!\n");
return 1;
}
int charlie(int alpha) {
if (alpha <= 0)
return bravo();
else
return alpha * charlie(alpha - 1);
}
int main(void) {
int delta = 0;
delta = charlie(3);
printf("delta = %d\n", delta);
return 0;
}
Förslag på lösning:
Förslag på lösning:
create, table, integer, char, primary, key, komma (","), vänsterparentes ("("), högerparentes (")") och namn.
b) Ange reguljära uttryck för de terminaler som inte har ett fast utseende.
Förslag på lösning:
namn: [a-zA-Z][a-zA-Z0-9]*
heltal: [0-9]+
Förslag på lösning:
Terminaler skrivs med fetstil, och icke-terminaler kursiverade. *tomt* står för en tom följd av terminaler och icke-terminaler.
kommando -> create table namn '(' kolumner ')'
kolumner -> kolumn ',' kolumner
kolumner -> kolumn
kolumn -> namn datatyp valfri_pk
datatyp -> integer
datatyp -> char '(' heltal ')'
valfri_pk -> primary key
valfri_pk -> *tomt*
create table kaffekoppar (nummer integer primary key, beskrivning char(100))
Förslag på lösning:
Förslag på lösning:
Grammatiken från uppgift 7 ovan innehåller en FIRST()-konflikt:
kolumner -> kolumn ',' kolumner kolumner -> kolumn
För att kunna skriva en prediktiv recursive-descent-parser måste vi först ta bort FIRST()-konflikten genom att vänsterfaktorisera. Ny version:
kolumner -> kolumn fler_kolumner fler_kolumner -> ',' kolumn fler_kolumner fler_kolumner -> *empty*
Hela den nya grammatiken:
kommando -> create table namn '(' kolumner ')'
kolumner -> kolumn fler_kolumner
fler_kolumner -> ',' kolumn fler_kolumner
fler_kolumner -> *empty*
kolumn -> namn datatyp valfri_pk
datatyp -> integer
datatyp -> char '(' heltal ')'
valfri_pk -> primary key
valfri_pk -> *tomt*
Ladda ner: sqlparser.c, plus en hjälpfil i form av en Lex-scannerspecifikation sql.l
#include <stdlib.h>
#include <stdio.h>
#include "sql.tab.h" // Bara för att få tokenkoderna
// %token CREATE TABLE PRIMARY KEY INTEGER CHAR NAMN HELTAL DONE
extern int yylex(void);
int lookahead;
int scan(void) {
return yylex();
}
void error() {
printf("Det har tyvärr uppstått ett fel.\n");
exit(EXIT_FAILURE);
}
void match(int expected) {
if (lookahead != expected)
error();
else
lookahead = scan();
}
void kommando(void), kolumner(void), fler_kolumner(void), kolumn(void), datatyp(void), valfri_pk(void);
void kommando(void) {
match(CREATE); match(TABLE); match(NAMN); match('('); kolumner(); match(')');
}
void kolumner(void) {
kolumn(); fler_kolumner();
}
void fler_kolumner(void) {
if (lookahead == ',') {
match(','); kolumn(); fler_kolumner();
}
else {
// Tomt
}
}
void kolumn(void) {
match(NAMN); datatyp(); valfri_pk();
}
void datatyp(void) {
if (lookahead == INTEGER) {
match(INTEGER);
}
else if (lookahead == CHAR) {
match(CHAR); match('('); match(HELTAL); match(')');
}
else {
error();
}
}
void valfri_pk(void) {
if (lookahead == PRIMARY) {
match(PRIMARY); match(KEY);
}
else {
// Tomt
}
}
void parse() {
lookahead = scan();
kommando();
printf("Ok.\n");
}
int main() {
printf("Mata in ett kommando. Avsluta med EOF.\n");
parse();
}
// Behövs för Lex
int yywrap(void) {
return 1;
}


{kind=link}