| Observera: Det finns sju uppgifter på tentan, men alla ska inte lösas. Svara på uppgift 1 och (högst) fem av de övriga sex uppgifterna. (Skulle du svara på alla sex, räknas den med högst poäng bort.) |
gå, skjut, ge, upp, börja, om, tal, komma, semikolon, radslut
b) (5p)
En lösning:
En annan lösning:kommandorad -> kommandolista radslut kommandolista -> kommando | kommando semikolon kommandolista kommando -> ga tal | skjut tallista | ge upp | börja om tallista -> tal | tal komma tallista
kommandorad -> kommandolista radslut kommandolista -> kommandolista semikolon kommando | kommando kommando -> ga tal | skjut tallista | ge upp | börja om tallista -> tallista komma tal | tal
c) (2p)
Grammatiken i den första lösningen ovan är inte vänsterrekursiv, men de två produktionerna på rad 2 har FIRST()-konflikter, och de två produktionerna på rad 4 har FIRST()-konflikter. Två olika vänsterfaktorisering ger en ny grammatik:
kommandorad -> kommandolista radslut kommandolista -> kommando flerakommandon flerakommandon -> semikolon kommandolista | empty kommando -> ga tal | skjut tallista | ge upp | börja om tallista -> tal fleratal fleratal -> komma tallista | empty
Så här gjorde vi vänsterfaktoriseringarna. Man skriver om dessa två produktioner, där A är en icke-terminal och x, y och z står för godtyckliga sekvenser av terminaler och icke-terminaler:
till dessa tre produktioner, där R är en ny icke-terminal:A -> x y | x z
A -> x R R -> y | z
Grammatiken i den andra lösningen är vänsterrekursiv, både för kommadolista och tallista. Efter att ha eliminerat vänsterrekursionen får vi:
kommandorad -> kommandolista radslut kommandolista -> kommando flerakommandon flerakommandon -> semikolon kommando flerakommandon | empty kommando -> ga tal | skjut tallista | ge upp | börja om tallista -> tal fleratal fleratal -> komma tal fleratal | empty
Så här gjorde vi när vi eliminerade vänsterrekursionen. Man skriver om dessa två produktioner, där A är en icke-terminal och x, y och z står för godtyckliga sekvenser av terminaler och icke-terminaler:
till dessa tre produktioner, där R är en ny icke-terminal:A -> A x | y
(De båda transformerade grammatikerna är ekvivalenta. Övning: Visa detta!)A -> y R R -> x R | empty
d) (6p)
Vi använder här den fördsta (transformerade) grammatiken.
int lookahead;
void error() {
printf("Ledsen error.\n");
exit(EXIT_FAILURE);
}
void match(int expected) {
if (lookahead != expected)
error();
else
lookahead = scan();
}
extern void kommandorad(), kommandolista(), flerakommandon(), kommando(), tallista(), fleratal();
void kommandorad() {
printf("kommandorad\n");
kommandolista(); match(RADSLUT);
printf("kommandorad klar\n");
}
void kommandolista() {
printf("kommandolista\n");
kommando(); flerakommandon();
}
void flerakommandon() {
printf("flerakommandon\n");
if (lookahead == SEMIKOLON) {
match(SEMIKOLON); kommandolista();
}
else {
/* Matchar empty, dvs nästa token kan vara vad som helst */
}
}
void kommando() {
printf("kommando\n");
if (lookahead == GA) {
match(GA); match(TAL);
}
else if (lookahead == SKJUT) {
match(SKJUT); tallista();
}
else if (lookahead == GE) {
match(GE); match(UPP);
}
else if (lookahead == BORJA) {
match(BORJA); match(OM);
}
else
error();
}
void tallista() {
printf("tallista\n");
match(TAL); fleratal();
}
void fleratal() {
printf("fleratal\n");
if (lookahead == KOMMA) {
match(KOMMA); tallista();
}
else {
/* Matchar empty, dvs nästa token kan vara vad som helst */
}
}
void parse() {
printf("parse\n");
lookahead = scan();
kommandorad();
printf("Ok.\n");
}
int main() {
parse();
return 0;
}
Spårutskrifterna, som skriver ut namnen på icke-terminaler, behöver förstås inte vara med.
| Token | Reguljärt uttryck |
|---|---|
| gå | gå |
| skjut | skjut |
| ge | ge |
| upp | upp |
| börja | börja |
| om | om |
| tal | [0-9]+ |
| komma | , |
| semikolon | ; |
| radslut | \n |
b) (2p)
Ett lexem är den teckensekvens i källprogrammet som motsvarar en token. Exempel på lexem:
Ett lexikaliskt värde är det interna värde som scannern ger till en hittad token, som komplement till dess typ. Lexemet kalle kanske ger tokentypen 273, som betyder att det är en identifierare, och det lexikaliska värdet 23, som betyder att det är identifierare nummer 23 i symboltabellen.
Bägge används av scannern: lexemet är en del av scannerns indata, och det lexikaliska värdet är en del av dess utdata.
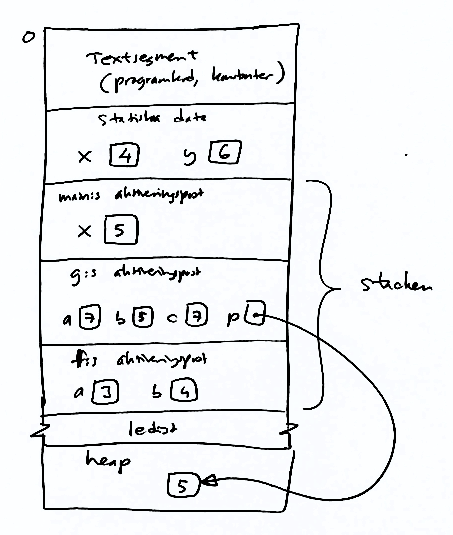
För varje proceduranrop skapas en aktiveringspost på stacken, och den innehåller procedurens lokala variabler och parametrar med (från början) de aktuella argumenten. På bilden växer stacken nedåt.
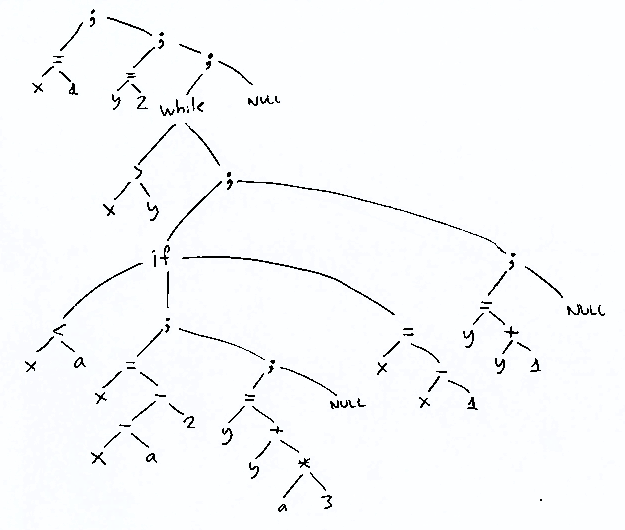
b) postfixkod för en stackmaskin
lvalue x push 1 = lvalue y push 2 = label 1: // Början på while-loopen rvalue x rvalue y > gofalse 2 rvalue x rvalue a < gofalse 3 lvalue x rvalue x rvalue a − push 2 − = lvalue y rvalue y rvalue a push 3 * + = goto 4 label 3: // Else-grenen i if-satsen lvalue x rvalue x push 1 − = label 4: // Efter if-satsen lvalue y rvalue y push 1 + = jump 1 label 2: // Efter while-loopen
Både i koden ovan och i treadresskoden nedan, behöver programlägena ("labels") inte vara egna instruktioner, utan de kan bara vara namn på en plats i programmet (dvs en annan instruktion).
c) treadresskod
x = 1; y = 2; label 1: // Början på while-loopen if (x <= y) goto 2; if (x >= a) goto 3; temp1 = x − a; temp2 = temp1 − 2; x = temp2; temp3 = a * 3; temp4 = y + temp3; y = temp4; goto 4; label 3: // Else-grenen i if-satsen temp5 = x − 1; x = temp5; label 4: // Efter if-satsen temp6 = y + 1; y = temp6; goto 1; label 2: // Efter while-loopen
Här antog jag att treadresskodgeneratorn var tillräckligt smart att vända på villkoren i de två villkorliga hoppen. Annars får man lägga resultaten av jämförelserna i en temporärvariabel, och hoppa om falskt:
temp7 = x > y; if (temp7 == false) goto 2; temp8 = x < a) goto 3; if (temp8 == false) goto 3;
Produktion:
Tillhörande semantisk regel, om vi antar att vi dekorerar parse-trädet med attributen plats och kod, samt att instr kan användas för att skapa nya treadressinstruktioner, och att + kan kedja ihop instruktioner och instruktionssekvenser:sats -> if ( uttryck ) then sats1 else sats2 endif
int elselabel = get_new_label();
int afterlabel = get_new_label();
sats.kod = uttryck.kod +
instr(if (uttryck.plats == false) goto elselabel) +
sats1.kod +
instr(goto afterlabel) +
instr(label elselabel) +
sats2.kod +
instr(label afterlabel);
Vi gör ingen smart vändning på villkoret (se deluppgift 5c).
Nu stod det visst for-sats i uppgiften. Jaja. Då blir det så här i stället:
Produktion:
Tillhörande semantisk regel:sats -> for ( uttryck1 ; uttryck2 ; uttryck3 ) sats1
int beforelabel = get_new_label();
int afterlabel = get_new_label();
sats.kod = uttryck1.kod +
instr(label beforelabel) +
uttryck2.kod +
instr(if (uttryck2.plats == false) goto afterlabel) +
sats1.kod +
uttryck3.kod +
instr(goto beforelabel) +
instr(label afterlabel);
En sorts mellankod som en del kompilatorer använder för att internt representera programmet, bland annat för att underlätta optimering. Den består av enkla, maskinoberoende instruktioner, där varje instruktion använder högst tre operander. En operand är en minnesplats (antingen ett programläge eller en variabel, som i sin tur antingen kommer från källprogrammet eller är en temporärvariabel genererad av kompilatorn), men kan också vara en konstant.
Exempel på treadressinstruktioner:
temp3 = temp1 + temp2; temp3 = temp1 + 2; y = temp3; if (x <= y) goto 2; goto 4;
b) (1p)
En sekvens av treadressinstruktioner som alltid kommer att utföras i ordning. Blocket får därför inte ha några hopp vare sig ut ur blocket eller in till det, förutom att hopp är tillåtna utifrån och till den första instruktionen, och att den sista instruktionen i blocket kan vara en hoppinstruktion. Basic blocks är viktiga för optimeraren.
Som exempel är det här inte ett basic block, eftersom det finns ett villkorligt hopp mitt i. Utan detta hopp blir det ett basic block, i alla fall om vi antar att det inte kan ske några hopp till instruktioner inuti blocket.
temp3 = temp1 + temp2; temp3 = temp1 + 2; y = temp3; if (x <= y) goto 2; goto 4;
c) (3p)
| kan optimeras till |
|
| kan ändras till |
|
| kan ändras till |
|
| kan optimeras till |
|