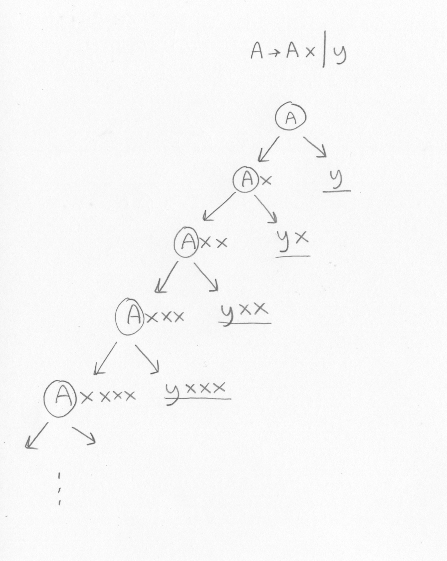
Det här avsnittet handlar om hur man ibland måste skriva om sin grammatik för att kunna skriva en parser.
Innan du läser det här avsnittet bör du kunna följande:
Stegen i sammanfattning:
Grammatiken är vänsterrekursiv. Den innehåller nämligen den här vänsterrekursiva produktionen:uttryck -> uttryck + term | term term -> id | num
Om vi skriver en prediktiv recursive-descent-parser utgående från den grammatiken, kommer den att innehålla en procedur som heter uttryck, och som börjar så här:uttryck -> uttryck + term
void uttryck() {
if (lookahead == num or lookahead == id) {
uttryck(); match('+'); term();
}
else
...
Vad händer?
Antag följande källprogram:
Detta källprogram kommer scannern att översätta till följande token-sekvens:2+2+2;
När vi ska börja parsa källprogrammet är det num som är aktuell token, eller lookahead-token.num + num + num ;
När funktionen uttryck anropas, visar det sig att lookahead är lika med num. Alltså går vi in i den första grenen i if-satsen, och vi anropar funktionen uttryck.
När funktionen uttryck anropas, visar det sig att lookahead är lika med num. Alltså går vi in i den första grenen i if-satsen, och vi anropar funktionen uttryck.
När funktionen uttryck anropas, visar det sig att lookahead är lika med num. Alltså går vi in i den första grenen i if-satsen, och vi anropar funktionen uttryck.
...
Eftersom inga tokens förbrukas, "står parsern och stampar" på det första num. Inga tokens förbrukas, och därför fastnar programmet i en oändlig rekursion.
Andra typer av parsers, till exempel en sådan som skapas av verktyget Yacc, klarar av vänsterrekursiva regler, men en recursive-descent-parser av den typ vi sett här klarar det inte. Alltså måste man skriva om grammatiken.
En vänsterrekursiv regel kan enkelt skrivas om till ett par andra regler, som inte är vänsterrekursiva. Antag att grammatiken ser ut så här:
A är en icke-terminal, men x och y kan stå för godtyckliga konstruktioner, med flera terminaler och icke-terminaler.A -> A x | y
Regeln ersätts av följande två regler, som beskriver samma språk men som inte är vänsterrekursiva:
A -> y R R -> x R | empty
Exempel: Den här vänsterrekursiva grammatiken,
kan skrivas om till denna, som inte är vänsterrekursiv:uttryck -> uttryck + term | term
I det här exemplet motsvarades A, x, y och R alltså av:uttryck -> term rest rest -> + term rest | empty
Vilket språk beskriver den här grammatiken? Eller, annorlunda uttryckt, vilka program kan man generera utifrån den?A -> A x | y
Vi antar att det är A som är startsymbol. Vi kan generera alla tillåtna program genom att gång på gång expandera icke-terminalerna. Det blir ett träd som ser ut så här (men notera att detta inte är ett parse-träd eller ett syntaxträd, utan det är ett träd som visar vad grammatiken tillåter):
De understrukna uttrycken kan inte expanderas vidare. Vi ser ett mönster: Det som den här grammatiken beskriver är program som består av ett y följt av noll, ett eller flera x.
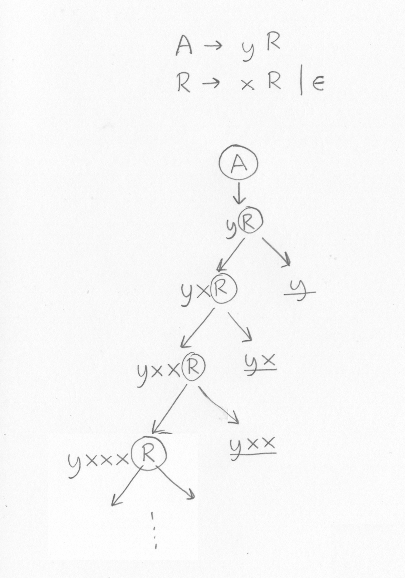
I förra avsnittet sa vi att vi kunde skriva om den vänsterrekursiva grammatiken till följande grammatik, som beskriver samma språk men som inte är vänsterrekursiv:
Om allt är rätt ska den alltså också beskriva program som består av ett y följt av noll, ett eller flera x:A -> y R R -> x R | empty
Exempelvis ska följande källprogram kunna parsas: 2, 2+3, 2-3, 2-3+4+5-6
ASU-86 figur 2.13/2.19 visar det översättningsschema (dvs en grammatik med inlagda semantiska aktioner) som man utgår från:
uttryck -> uttryck + term { print('+') }
uttryck -> uttryck - term { print('-') }
uttryck -> term
term -> 0 { print('0') }
term -> 1 { print('1') }
term -> 2 { print('2') }
...
term -> 9 { print('9') }
(Kom ihåg att en regel som term -> term + term ger en tvetydig
(engelska: ambiguous) grammatik, så vi transformerade grammatiken.
Vi har också tidigare sett hur man hanterar operatorassociativitet och
operatorprioritet.)
Nu skriver vi om grammatiken för att eliminera vänsterrekursionen.
Viktigt: Man ska hantera de semantiska aktionerna som en del av grammatiken,
när man skriver om den enligt tekniken ovan för eliminering av vänsterrekursion!
Annars kommer utskrifterna att hamna på fel plats.
Så här blir resultatet:
uttryck -> term rest
rest -> + term { print('+') } rest
rest -> - term { print('-') } rest
rest -> empty
term -> 0 { print('0') }
term -> 1 { print('1') }
term -> 2 { print('2') }
...
term -> 9 { print('9') }
De två reglerna för addition och subtraktion var båda vänsterrekursiva,
och har därför transformerats.
I fallet med regeln för addition motsvarades
A, x, y och R av:
void term () {
if (isdigit(lookahead)) {
putchar(lookahead);
match(lookahead);
}
else
error();
}
void rest() {
if (lookahead == '+') {
match('+'); term(); putchar('+'); rest();
}
else if (lookahead == '-') {
match('-'); term(); putchar('-'); rest();
}
else
;
}
void uttryck() {
term(); rest();
}
Den fullständiga källkoden: 2.5
Antag som exempel att en kapten kan ropa fyra olika kommandon till sina soldater: "halt", "framåt marsch", "eld" och "eld upphör". Det kan beskrivas med följande grammatik:
Om man är soldat och hör kaptenen ropa framåt, så vet man att kommandot som kaptenen ropar kommer att vara framåt marsch. Men om man hör kaptenen ropa ett kommando som börjar med eld, så vet man inte redan då om kommandot är eld eller eld upphör. Man måste vända tills man hör nästa ord.kommando -> halt kommando -> framåt marsch kommando -> eld kommando -> eld upphör
En soldat kan kanske lösa det där genom att vänta en stund och se vad kaptenen ropar efter att ha ropat eld. En recursive-descent-parser har det värre, för den har ju en procedur för varje icke-terminal, och i procedureren väljer parsern vilken produktion som icke-terminalen ska expanderas med genom att köra den gren i en if-sats som motsvarar den produktionen. Vad ska den köra för kod om den inte vet vilken som är rätt?
Om man hittar en identifierare, till exempel a i källprogrammet, på ett ställe där det ska stå en sats, så vet man alltså inte om det där a:et är början på en tilldelning eller på ett uttryck.sats -> tilldelning | uttryck tilldelning -> id = uttryck <-- Börjar alltid med id uttryck -> term fler-termer <-- Kan bärja med id ...
| Hittat i källprogrammet | Vad kommer sen? | Det betyder att "a" är början på... |
|---|---|---|
| a | = 5 ... + 5 ... | En tilldelning Ett uttryck |
Just det här fallet kan hanteras med två-tokens-lookahead, dvs att man tittar inte bara på aktuell token utan även på nästa, i stället för en-tokens-lookahead.
Men den lösningen fungerar inte alltid. Om vi till exempel har en lite mer avancerad grammatik, som påminner mer om språket C, och som tillåter tilldelningar av typen a[7] = 8 eller a[i+2] = 8, så hjälper det inte med två-tokens-lookahead:
| Hittat i källprogrammet | Vad kommer sen? | Det betyder att "a" är början på... |
|---|---|---|
| a[3+4+z] | = 5 ... + 5 ... | En tilldelning Ett uttryck |
Vi kan alltså behöva hur många tokens lookahead som helst.
Det man gör i stället är att pröva med en av reglerna,
och om det (till sist) visar sig att den regeln inte gick att använda,
så går man tillbaka ("backtrackar") och försöker i stället med den andra.
Det är krångligt att göra med ett C-program, men det går.
Men det är värre än så. Det räcker inte alltid med att komma ihåg ett enda val, som man kanske måste gå tillbaka till och ändra, utan det kan komma flera val efter varandra, innan vi vet om det första valet var rätt eller fel.
Exempelvis kan vi i ett riktigt C-program kan vi skriva tilldelningar av typen a[b[3] = 9] = 8, som betyder att först placerar vi värdet 9 i position 3 i arrayen b, och sen tar vi värdet av det tilldelningsuttrycket, som är 9 (om b är en heltalsarray) och använder som index i arrayen a, dvs vi placerar värdet 8 i position 9 i arrayen a.
| Hittat i källprogrammet | Vad kommer sen? | Det betyder att "a" är början på... |
|---|---|---|
| a[b[5+6] | = 5 ... + 5 ... | En tilldelning Ett uttryck |
Vi får alltså ett träd av valmöjligheter, och vi måste hålla reda på hur långt tillbaka i det trädet vi ska gå tillbaka.
Andra typer av parsers, till exempel en sådan som skapas av verktyget Yacc,
klarar av grammatiker som innehåller FIRST()-konflikter,
men en recursive-descent-parser av den typ vi sett här klarar det inte.
Alltså måste man skriva om grammatiken.
Ett exempel på FIRST()-konflikt är den här grammatiken, som beskriver en
if-sats med en valfri else-gren:
Kommer ni ihåg tricket för att ta bort vänsterrekursion?
En liknande metod, vänsterfaktorisering,
kan användas för att ta bort en FIRST()-konflikt.
Man kan skriva om grammatiken så här:
Men för enkla grammatiker, som för en kalkylator eller ett sökfält på en webbsida,
behöver man ibland skriva parsern själv, för hand.
Det kan vara svårt att plugga in Yacc i en ASP-sida eller ett Perl-script.
Titta på följande exempel, där sökfraser, med sökord, or, and
och parenteser, ska översättas till SQL-frågor att köras mot en databas
med vilka ord som finns i vilka dokument.
Vänsterfaktorisering
(Se också ASU-86 avsnitt 4.3, Writing a grammar, s 178-179.)
sats -> if ( uttryck ) sats
| if ( uttryck ) sats else sats
Så här gör man vänsterfaktorisering.
Skriv om dessa två (ja, två) produktioner:
sats -> if ( uttryck ) sats valfir-else-gren
valfir-else-gren -> else sats | empty
till dessa tre (ja, tre) produktioner:
A -> x y | x z
Innan man kan skriva en prediktiv recursive-descent-parser,
ska man alltså skriva om sin grammatik så att den:
A -> x R
R -> y | z
Varför hålla på så här när man slipper det med verktyg som Yacc?
De här transformationerna kan naturligtvis vara besvärliga,
särskilt om man har en stor grammatik med många produktioner.
Därför brukar man inte vilja bygga mer komplicerade parsers för hand,
utan man använder verktyg som Yacc eller Bison.
| Sökfras | SQL-fråga |
|---|---|
| cinema |
select d.Nr
from Document d, Occurs o, Word w where d.Nr = o.Document and o.Word = w.Number and w.Text = 'cinema' |
| cinema Örebro |
select Document.Nr
from Document d, Occurs o1, Occurs o2, Word w1, Word w2 where (d.Nr = o1.Document and o1.Word = w1.Number and w1.Text = 'cinema') and (d.Nr = o2.Document and o2.Word = w2.Number and w2.Text = 'Örebro') |
| (cinema or museum) and Örebro |
select Document.Nr
from Document d, Occurs o1, Occurs o2, Occurs o3, Word w1, Word w2, Word w3 where ((d.Nr = o1.Document and o1.Word = w1.Number and w1.Text = 'cinema') or (d.Nr = o2.Document and o2.Word = w2.Number and w2.Text = 'Örebro')) and (d.Nr = o3.Document and o3.Word = w3.Number and w3.Text = 'Örebro') |