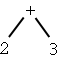
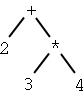
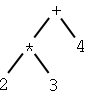
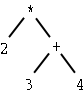
Today:
More about syntax analysis ("parsing"),
Aho et al, sections 2.1 - 2.4
But first: Rest from lecture 1:
More rest from lecture 1:
| Tree | Infix notation | Postfix notation |
|---|---|---|
|
| 2 + 3 | 2 3 + |
|
| 2 + 3 * 4 | 2 3 4 * + |
|
| 2 * 3 + 4 | 2 3 * 4 + |
|
| 2 * (3 + 4) | 2 3 4 + * |
Source and target as text.
Postfix: Stack machine. Easy to write an interpreter.
The "2.5" program:
simple grammar (Sw: "grammatik") (only + and -),
simple parser, very simple scanner (one character = one token).
The "2.9" program:
more advanced grammar (identifiers, *, /, mod, div),
therefore a more complex parser, a "real" scanner.
if (a == b)
printf("Same!\n");
else
printf("Not same!\n");
This, as you know, is the syntax for the if statement:
if ( some expression ) some statement else some other statement
A rule that could be part of a context-free grammar (Sw: kontextfri grammatik) for C:
statement -> if ( expression ) statement else statement
statement -> if ( expression ) statement
statement -> { statement-list } (forgot what?)
...
"Context-free": a production "X -> ..." can always be used to replace X with "...", no matter what the rest of the program (that is, the context, Sw: kontext, omgivning) looks like.
digit -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
list -> digit
list -> list + digit
list -> list - digit
or
digit -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
list -> digit | list + digit | list - digit
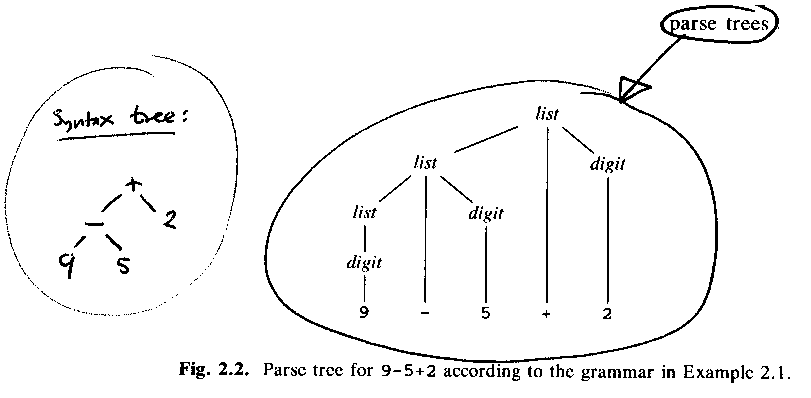
Try 9-5+2.
9 -> digit -> list.
5 -> digit.
9-5 -> list - digit -> list
2 -> digit.
9-5+2 -> list + digit -> list
ASU fig 2.2, the parse tree (= concrete syntax tree) and the syntax tree (= abstract syntax tree):
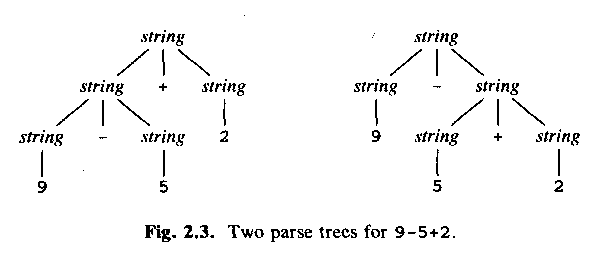
Why list + digit etc? Asymmetrical and ugly? Why not just list + list, like this:
digit -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
string -> string | string + string | string - string
ASU fig 2.3 (slide!):
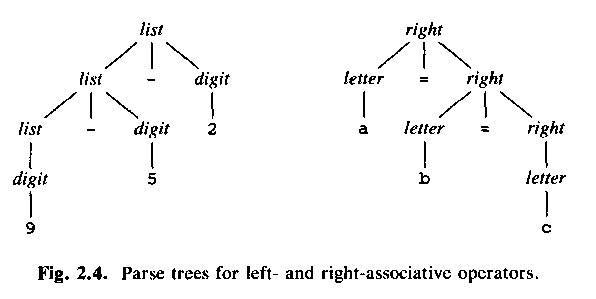
Use a grammar like above, that is,
list -> list + digit
for left-associative (Sw: vänsterassociativa) operators.
Use a grammar like
list -> digit + list
for right-associative (Sw: högerassociativa) operators, for example:
right -> letter = right
letter -> a | b | c | ... | z
Express this in the grammar:
factor -> digit | ( expr )
term -> term * factor | term / factor | factor
expr -> expr + term | expr - term | term
Two different types:
Syntax-directed definition = context-free grammar, plus a semantic rule (Sw: semantisk regel) for each production, that specifies how to calculate values of attributes. Example:
| Production | Semantic rule |
|---|---|
| term -> 0 | term.output -> " 1" |
| term -> 1 | term.output -> " 1" |
| term -> 2 | term.output -> " 2" |
| ... | ... |
| expr -> expr1 + term1 | expr.output -> expr1.output + term1.output + " +" |
| ... | ... |
ASU fig 2.6:
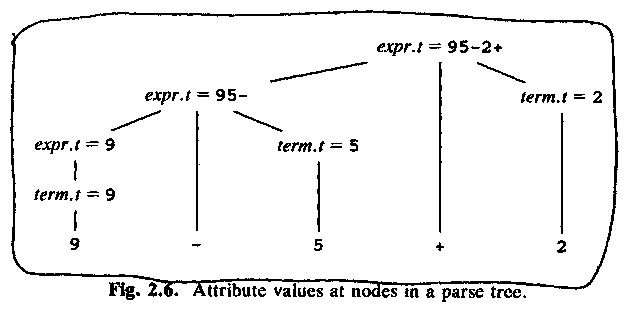
But a syntax-directed definition says nothing about how the parser should build the parse tree! Just the grammar, and what to do when we have found which production to use.
Syntax-directed definition = context-free grammar, plus semantic actions (Sw: semantiska aktioner, semantiska åtgärder) for each production, that specifies what to do. Example:
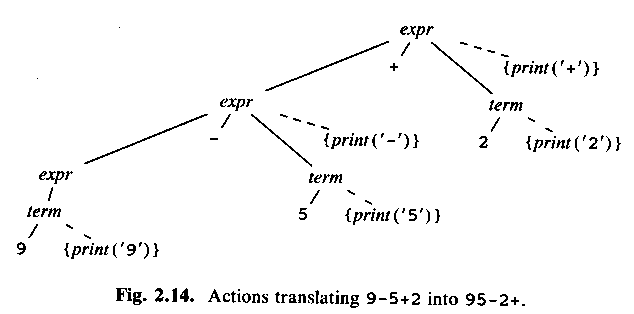
expr -> expr1 + term1 { print("+"); }
Generates postfix!
Or, with the action somewhere in the middle:
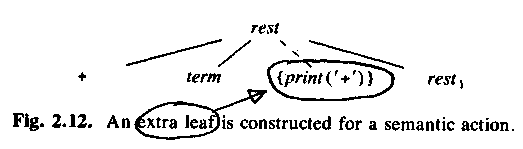
rest -> + term1 { print("+"); } rest1
The semantic actions are put in the parse tree, just like the "real" parts. ASU fig 2.12:
ASU fig 2.14:
...............
Recursive-descent parsing = the parser is a program with a procedure (in C: "function") for each non-terminal
current token, lookahead symbol
backtracking
FIRST(some-nonterminal)
Left-recursion
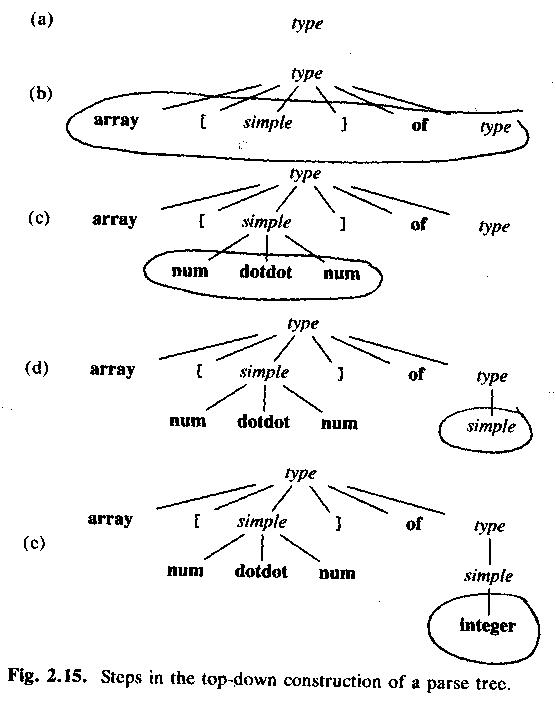
ASU fig 2.15:
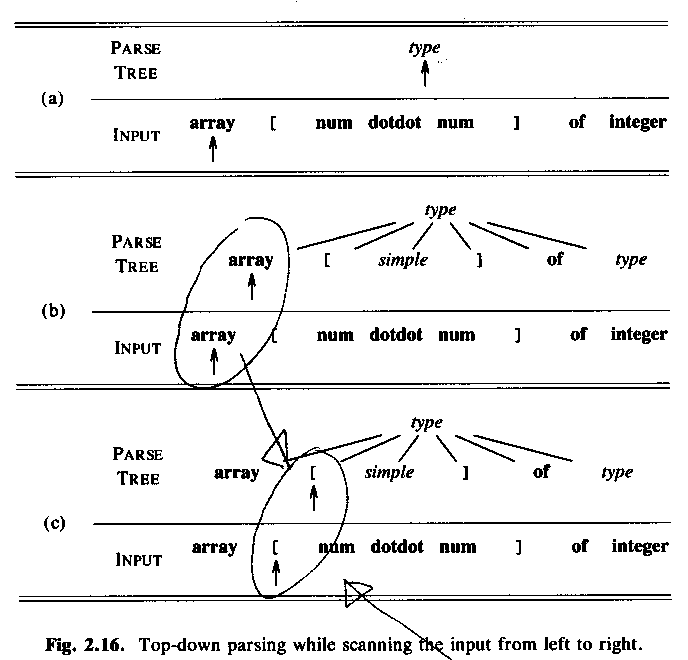
ASU fig 2.16: