Observera att detta är förslag på lösningar. Det kan finnas andra lösningar som också är korrekta, och det kan hända att en del av lösningarna är mer omfattande än vad som krävs för full poäng på uppgiften.
Fråga -> Term | Fråga or TermAlternativ lösning, som inte tillåter "not not":
Term -> Faktor | Term and Faktor
Faktor -> sökord | not Faktor | ( Fråga )
Fråga -> Term | Fråga or TermAlternativ lösning, med vänsterrekursionen eliminerad:
Term -> Faktor | Term and Faktor
Faktor -> Grund | not Grund
Grund -> sökord | ( Fråga )
Fråga -> Term R1empty ska egentligen vara symbolen för en tom sträng, men den är svår att skriva i HTML så det blir rätt i alla webbläsare.
R1 -> or Term R1 | empty
Term -> Faktor R2
R2 -> and Faktor R2 | empty
Faktor -> sökord | not Faktor | ( Fråga )
ab, abb, abbb, abbbb, abbbbb, ad, acd, accd, acccd, accccd
b) 4p
Grammatiken innehåller två produktioner för S:
där FIRST(a X) och FIRST(a Y) båda är lika med { a }. Därför kan en prediktiv parser inte välja vilken regel som ska användas, i alla fall inte med en enda tokens lookahead.S -> a X S -> a Y
(Det är fel svar att skriva att grammatiken är tvetydig. En tvetydig grammatik är en som kan ge flera olika parse-träd för samma tokensekvens.)
Produktionen
innehåller vänsterrekursion. En recursive-descent-parser som parsar en sträng, och ska matcha icke-terminalen X, anropar proceduren X. I den proceduren avgörs att källsträngen matchar högerledet X b. Därefter ska det högerledet matchas, och vi börjar med att matcha X genom att anropa proceduren X. Och nu är vi alltså tillbaka i samma procedur, utan att ha "förbrukat" några tokens i inmatningen, och så håller det på i en oändlig rekursion.X -> X b
c) 4p
Vänsterfaktorisering:
A -> x y | x z
blir
A -> x R
och
R -> y | z
(Fel svar:
A -> x y | x
blir
A -> x R
och
R -> y | empty.
Det är bara i just den här grammatiken som det råkar vara så att z är tom.)
Eliminering av vänsterrekursion:
A -> A x | y
blir
A -> y R
och
R -> x R | empty
(Fel svar:
A -> A x | x
blir
A -> x R
och
R -> x R | empty.
Det är bara i just den här grammatiken som det råkar vara så att x = y.)
Resultat av omvandlingen:
S -> a R1 R1 -> X | Y X -> b R2 R2 -> b R2 | empty Y -> c Y | d
(Notera att både x och y var lika med b när vi eliminerade vänsterrekursionen.)
d) 6p
int lookahead;
void error() {
printf("Ledsen error.\n");
exit(EXIT_FAILURE);
}
void match(int expected) {
if (lookahead != expected)
error();
else
lookahead = scan();
}
void S() {
match('a');
R1();
}
void R1() {
if (lookahead == 'b')
X();
else if (lookahead == 'c' || lookahead == 'd')
Y();
else
error();
}
void X() {
match('b');
R2();
}
void R2() {
if (lookahead == 'b') {
match('b');
R2();
}
else {
/* Match empty */
}
}
void Y() {
if (lookahead == 'c') {
match('c');
Y();
}
else if (lookahead == 'd')
match('d');
else
error();
}
void parse() {
lookahead = scan();
S();
}
Alternativ lösning, med de optimeringar som görs i kursboken:
int lookahead;
void error() {
printf("Ledsen error.\n");
exit(EXIT_FAILURE);
}
void match(int expected) {
if (lookahead != expected)
error();
else
lookahead = scan();
}
void S() {
match('a');
if (lookahead == 'b')
X();
else if (lookahead == 'c' || lookahead == 'd')
Y();
else
error();
}
void X() {
match('b');
while (1) {
if (lookahead == 'b')
match('b');
else
break;
}
}
void Y() {
while (1) {
if (lookahead == 'c')
match('c');
else if (lookahead == 'd') {
match('d');
break;
}
else
error();
}
}
void parse() {
lookahead = scan();
S();
}
Några korrekta svar: abb*|ac*d eller ab+|ac*d eller a(b+|c*d)
b) 2p
Någon grammatik som innehåller rekursion, till exempel:
(Matchar 0-n stycken a, följt av lika många b.)S -> a S b | empty
Ett vanligt fel: Fel associativitet på minus, så att delträdet längst till höger beräknar h-(i-j) i stället för (h-i)-j.
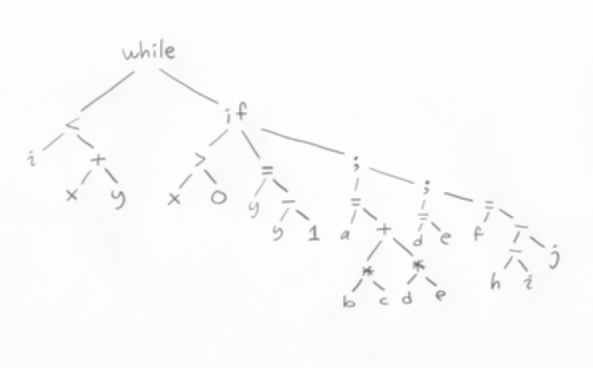
b)
FL: i
x
y
+
<
jumpfalse EL
x
0
>
jumpfalse EG
lvalue y
y
1
-
=
jump EE
EG: lvalue a
b
c
*
d
e
*
+
=
lvalue d
e
=
lvalue f
h
i
-
j
-
=
EE: jump FL
EL:
c)
FL: t1 = x + y;
if (i >= t1) goto EL;
if (x <= 0) goto EG;
y = y - 1;
goto EE;
EG: t2 = b * c;
t3 = d * e;
a = t2 + t3
d = e;
t4 = h - i;
f = t4 - j;
EE: goto FL;
EL:
Sats -> while ( Uttryck ) do Sats1 od
{
label before = newlabel();
label after = newlabel();
Sats.code =
instruction(before + ":") +
Uttryck.code +
instruction("jumpfalse " + after) +
Sats1.code +
instruction("jump " + before) +
instruction(after + ":");
}
| Id | Lexem | Typ | ... |
|---|---|---|---|
| 1 | s | string | |
| 2 | i | integer | |
| 3 | foo | integer | |
| 4 | fum | string |
Varje konstant och variabel som sen används i källprogrammet har en typ. För variablerna hämtas typen ur symboltabellen. När variabler och konstanter kombineras i uttryck, till exempel i tilldelningar och additioner, utgår man från dessa typer, och kontrollerar om de typkombinationerna är tillåtna för den aktuella operationen. Det kan göras med regler i en syntaxstyrd översättning.
Vi tänker oss att det finns två procedurer: addtype som lägger till en typ till en variabel lagrad i symboltabellen, och lookup som returnerar en symboltabellpost för en variabel. Den posten innehåller bland annat ett typfält, type.
De här semantiska aktionerna, eller motsvarande semantiska regler, behövs:
T -> "string"
{
T.type = string;
}
T -> "number"
{
T.type = number;
}
D -> "variable" id ":" T ";"
{
// Insert type of variable into symbol table
addtype(id.tokenval, T.type);
}
E -> id
{
// Get type of variable from symbol table
E.type = lookup(id.tokenval).type;
}
E -> string-constant
{
E.type = string;
}
E -> number-constant
{
E.type = number;
}
E -> E1 "+" E2
{
if (E1.type == string && E2.type == string)
E.type = string;
else if (E1.type == number && E2.type == number)
E.type = number;
else {
E.type = type_error;
error(...);
}
}
S -> id "=" E ";"
{
if (id.type = E.type)
S.type = void;
else {
S.type = type_error;
error(...);
}
}
Den innehåller lagringsutrymme för procedurens formella parametrar, dess lokala variabler, och temporärvariabler som används i proceduren. Den innehåller också plats för att lagra återhoppsadress och returnerat funktionsvärde. (Flera av alla dessa saker lagras ofta i stället i register.) Dessutom kan maskinstatus från den anropande funktionens exekvering, främst innehållet i processorns register, sparas undan i aktiveringsposten.
Det kan också finnas en "dynamisk länk", till aktiveringsposten för den procedur som anropade den här proceduren, och en "statisk länk", till en aktiveringspost för den procedur som närmast omsluter den här proceduren i programkoden.
För språk med enbart statisk allokering, som uråldriga versioner av FORTRAN, är aktiveringsposten för varje procedur statiskt allokerad. (Endast en aktiveringspost per procedur.) För "vanliga" språk som C, C++, Java och Pascal placeras aktiveringsposten på stacken. (En aktiveringspost per anrop till varje procedur.) Man kan också allokera aktiveringsposterna på heapen, till exempel i språk där man kan avbryta och återstarta exekveringen av en procedur.