 syntaxträd")
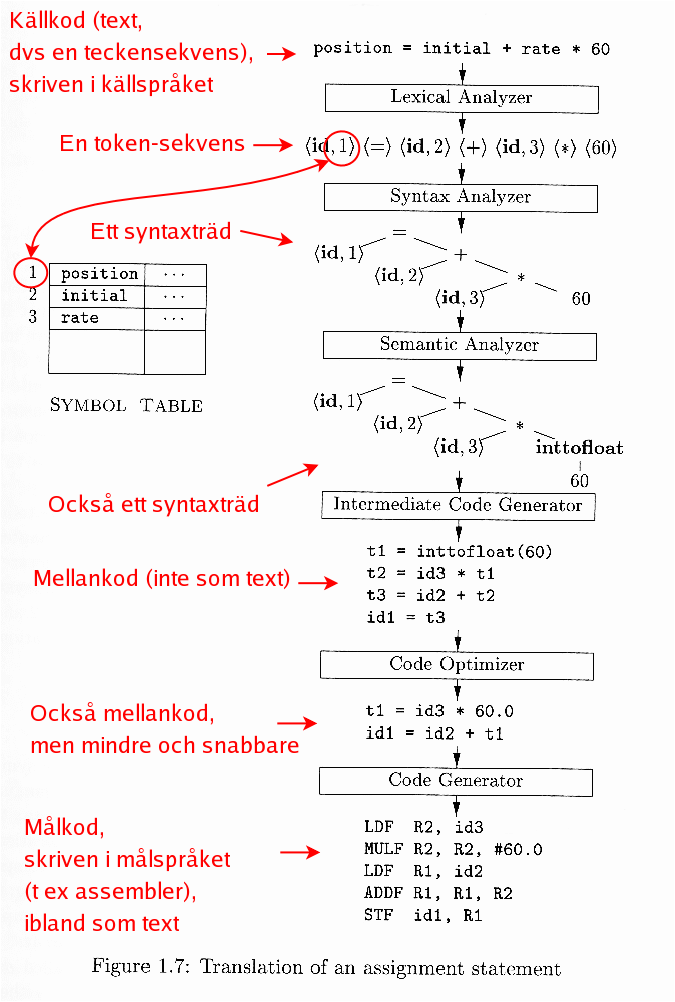
Se också boken eller föreläsningsanteckningarna, särskilt den här figuren, med tillägget att den maskinberoende optimeringen ger som utdata målkod i målspråket, men mindre och snabbare jämfört med den kod som är utdata från kodgeneratorn.
x = 0;
while (x < y) {
while (y < z) {
y = y + z + 1;
}
z = 2;
}
Översätt ovanstående programavsnitt till var och en av följande tre typer av mellankod.
a) ett syntaxträd, även kallat abstrakt syntaxträd (genom att rita upp trädet!)
En kommentar: Man kan avsluta ";-listorna" med NULL i stället för den sista satsen i listan. Det blir lite mer att rita, men kan vara lite enklare programmeringsmässigt.
b) postfixkod för en stackmaskin
lvalue x
push 0
assign
label 1:
rvalue x
rvalue y
lt
gofalse 2
label 3:
rvalue y
rvalue z
lt
gofalse 4
lvalue y
rvalue y
rvalue z
plus
push 1
plus
assign
goto 3
label 4:
lvalue z
push 2
assign
goto 1
label 2:
c) treadresskod
x = 0
label 1:
if (x ≥ y) goto 2
label 3:
if (y ≥ z) goto 4
temp1 = y + z
temp2 = temp1 + 1
y = temp2
goto 3
label 4:
z = 2
goto 1
label 2:
En kommentar: Man kan redan här optimera bort (eller snarare låta bli att generera) temporärvariabler i tilldelningar, så de två instruktionerna "temp2 = temp1 + 1" och "y = temp2" ovan i stället blir "y = temp1 + 1"
Namn, punkt (.), utropstecken (!) samt nyckelorden är, barn, till och Klart.
släktträd -> lista Klart utropstecken
lista -> föräldraskap | lista föräldraskap
föräldraskap -> namn är barn till namn punkt
Klas är barn till Sven. Sven är barn till Svea. Klart!
Nisse är barn till Nisse. Nisse är barn till Nisse. Nisse är barn till Nisse. Klart!Nisse är barn till sig själv, flera gånger om!
Förklara hur det påverkar parsningen!
Svar: Inte alls. I grammatiken står det bara om tokentypen namn, inget om vilka namn det är. Namn som namn! Analysen av hur släktträdet hänger ihop kommer senare, inte i parsningsfasen.
Det finns en vänsterrekursion i produktionen lista -> lista föräldraskap, så grammatiken måste först skrivas om för att eliminera den vänsterrekursionen:
släktträd -> lista Klart utropstecken
lista -> föräldraskap fler-föräldraskap
fler-föräldraskap -> föräldraskap fler-föräldraskap | ingenting
föräldraskap -> namn är barn till namn punkt
ingenting står för en tom produktion.
Ladda ner: slakttradsparser.c, plus en hjälpfil i form av en Lex-scannerspecifikation slakttrad.l.
#include <stdlib.h>
#include <stdio.h>
#include "slakttrad.tab.h" // Bara för att få tokenkoderna
// Från Bison: %token NAMN AR BARN TILL PUNKT KLART UTROPSTECKEN
extern int yylex(void);
int lookahead;
int scan(void) {
return yylex();
}
void error() {
printf("Det har tyvärr uppstått ett fel.\n");
exit(EXIT_FAILURE);
}
void match(int expected) {
if (lookahead != expected)
error();
else
lookahead = scan();
}
void slakttrad(void),
lista(void),
fler_foraldraskap(void),
foraldraskap(void);
void slakttrad(void) {
lista(); match(KLART); match(UTROPSTECKEN);
}
void lista(void) {
foraldraskap(); fler_foraldraskap();
}
void fler_foraldraskap(void) {
if (lookahead == NAMN) {
foraldraskap(); fler_foraldraskap();
}
else {
/* Ingenting */
}
}
void foraldraskap(void) {
match(NAMN); match(AR); match(BARN); match(TILL); match(NAMN); match(PUNKT);
}
void parse() {
lookahead = scan();
slakttrad();
printf("Ok.\n");
}
int main() {
printf("Mata in ett släktträd. Avsluta med \"Klart!\" och EOF.\n");
parse();
}
// Behövs för Lex
int yywrap(void) {
return 1;
}

{kind=link}