Observera att detta är förslag på lösningar.
Det kan finnas andra lösningar som också är korrekta,
och det kan hända att en del av lösningarna är mer omfattande
än vad som krävs för full poäng på uppgiften.
En del av lösningarna är inte fullständiga,
utan hänvisar bara till var man kan läsa svaret.
Uppgift 1 (3 p)
Se
Introduktion till databaser och databashanterare.
De viktigaste fördelarna med att använda en databashanterare är att det är
enkelt, kraftfullt och flexibelt,
men för att få poäng på frågan måste man också
förklara vad dessa reklamfraser egentligen innebär.
Uppgift 2 (3 p)
Se
Introduktion till databaser och databashanterare,
särskilt avsnittet med rubriken Tre-schema-arkitekturen.
Uppgift 3 (3 p)
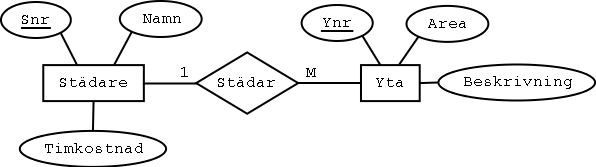
Uppgift 4 (4 p)
Tabellerna, med illustrativa exempel på data:
Städare
| Snr | Namn | Timkostnad |
|---|
| 1 | Hjalmar | 100 |
| 2 | Hulda | 150 |
| 3 | Saddam | 100 |
| 4 | Saddam | 1000 |
Yta
| Ynr | Beskrivning | Area | Städare |
|---|
| 10 | T1 | 2000 | 1 |
| 20 | T2 | 2000 | 1 |
| 30 | X1 | 100 | 3 |
| 40 | X2 | 100 | null |
create table-kommandon, som visar primärnyckel och referensattribut:
create table Stadare (
snr integer,
namn varchar(10),
timkostnad integer,
primary key (snr));
create table Yta (
ynr integer,
beskrivning varchar(10),
area integer,
stadare integer,
primary key (ynr),
foreign key (stadare) references Stadare (snr));
Uppgift 5 (7 p)
a (1p)
select * from Yta, Stadare
where Yta.stadare = Stadare.snr
and Yta.beskrivning = 'T1';
b (1p)
select * from Yta
where stadare is null;
c (2p)
select * from Stadare
where snr not in (select stadare from Yta);
d (3p)
select snr, namn
from Stadare, Yta
where Stadare.snr = Yta.stadare
group by snr, namn
having sum(area) > 40 * 60;
Uppgift 6 (4 p)
- Stadare.snr
- Yta.stadare
- Yta.beskrivning
Dessa används för sökningar, dvs (enkelt uttryckt) i where-villkoret, på frågorna.
Se även
Index och prestanda.
Uppgift 7 (5 p)
Tabellen bör innehålla en kolumn, städare,
som anger numret på en städare,
och en kolumn, totalyta,
som anger den städarens sammanlagda städyta.
De ändringar i databasen som kan påverka en städares sammanlagda städyta,
och som man därfår måste skriva triggers för, är
- insättning av en ny yta, med den städaren angiven som städare
- borttagning av en gammal yta, som hade den städaren angiven som städare
- ändring av arean på en yta, som har den städaren angiven som städare
- ändring av angiven städare på en yta, som antingen hade eller fick den städaren angiven som städare
En aktiv regel ("trigger") skapas för en viss tabell,
och för en av operationerna insert, delete och update.
Det behövs alltså fyra regler:
- En regel som körs vid insert i tabellen Yta.
Den regeln ska lägga till den ytans area till rätt städares totala städyta.
- En regel som körs vid delete i tabellen Yta.
Den regeln ska lägga dra bort ytans area från rätt städares totala städyta.
- En regel som körs vid update av tabellen Yta.
Om en ytas area har ändrats,
ska den gamla arean dras bort från rätt städares totala städyta,
och den nya arean ska läggas till.
- En regel som också körs vid update av tabellen Yta.
Om en yta får en ny städare,
ska dess area dras bort från den gamla städarens totala städyta,
och arean ska också läggas till den nya städarens totala städyta,
De två sista update-reglerna kan kombineras till en.
Uppgift 8 (3 p)
Man kan skapa under-typer av entitetstypen Yta:
en typ som heter Toalett, en som heter Korridor,
och så vidare.
Den lösningen är inte så bra, för den kräver ändringar i schemat
i form av en ny tabell
varje gång det behövs en ny typ av yta.
Man kan helt enkelt lägga till ett attribut Typ,
och kanske ett attribut Tidsfaktor,
till entitetstypen Yta.
Med den lösningen behöver man inte ändra i schemat
varje gång det behövs en ny typ av yta,
men å andra sidan har man ingen samlad lista på vilka typer av ytor som finns.
Tidsfaktorn kommer också att upprepas för varje yta som tillhör typen,
och kan inte lagras om det inte just nu finns några ytor av den typen.
Den bästa lösningen är en ny entitetstyp, kallad till exempel Typ av yta,
och en sambandstyp som låter varje Yta tillhöra en Typ av yta:
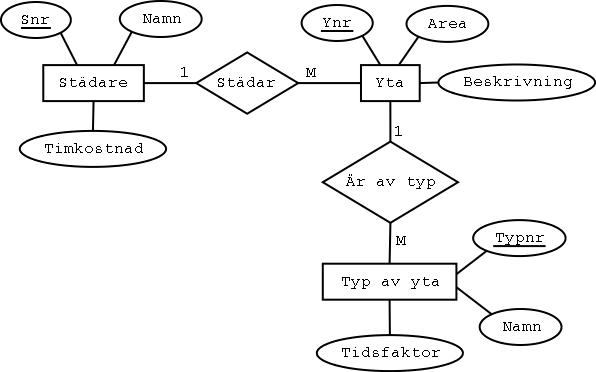
I relationsschemat kommer detta att innebära en ny kolumn i tabellen Yta,
och en ny tabell för Typ av yta:
Yta
| Ynr | Beskrivning | Area | Städare | Typ |
|---|
| 10 | T1 | 2000 | 1 | 1 |
| 20 | T2 | 2000 | 1 | 1 |
| 30 | X1 | 100 | 3 | 4 |
| 40 | X2 | 100 | null | 5 |
Yttyp
| Tnr | Namn | Tidsfaktor |
|---|
| 1 | Föreläsningssal | 1.2 |
| 2 | Klassrum | 1.3 |
| 3 | Korridor | 1.0 |
| 4 | Toalett | 5.0 |
| 5 | ABC-vapenlabb | 200 |
Uppgift 9 (4 p)
a)
Varje pil visar ett fullständigt funktionellt beroende:
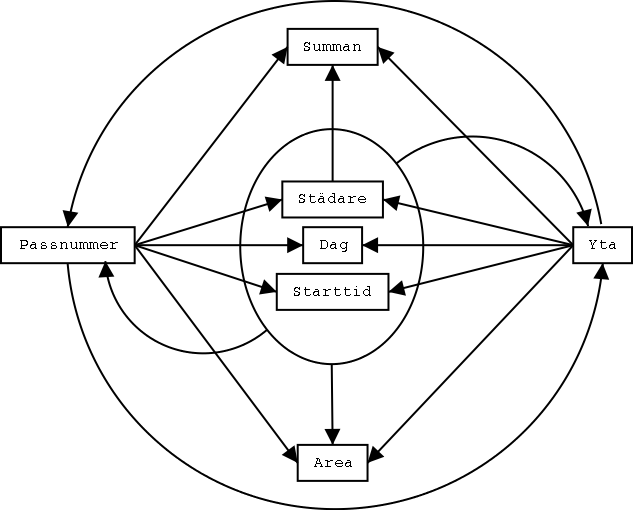
Tabellen har atomära värden, så 1NF är uppfylld.
Eftersom Städare, Dag och Starttid är en kandidatnyckel,
och Summan är ffb av Städare,
uppfylls inte 2NF.
2NF säger att inget icke-nyckel-attribut får vara ffb av en del i en kandidatnyckel.
Alltså är 1NF den högsta normalform som tabellen uppfyller.
b)
En determinant är en kolumn eller en kombination av kolumner
som någon annan kolumn är ffb av.
BCNF kräver att endast kandidatnycklar får vara determinanter.
Det enda som bryter mot detta är att Summan är ffb av Städare.
Därför bryter vi ut Städare och Summan till en egen tabell:
Arbetsschema
| Passnummer | Städare | Dag | Starttid | Yta | Area |
|---|
| 1 | 1 | Må | 08:00 | 7 | 30 |
| 2 | 1 | Må | 08:30 | 8 | 10 |
| 3 | 1 | Må | 08:45 | 11 | 100 |
| 4 | 2 | Må | 08:00 | 13 | 1000 |
Städarsumma
| Städare | Summa |
|---|
| 1 | 140 |
| 2 | 1000 |
(Tabellen Städarsumma kan slås ihop med tabellen Städare.
Alternativt kan man helt strunta i att lagra summan, eftersom den kan härledas ur andra data.
I bägge fallen behövs inte tabellen Städarsumma.)
c)
Problem:
- Redundans. Summan per städare återkommer en gång i den ursprungliga tabellen
för varje yta som den städaren städar.
Eftersom varje städare finns på en enda rad i tabellen Städsumma,
-
Svårighet att lagra data:
När en städare inte städar några ytor,
går det i den ursprungliga tabellen inte att lagra att hans sammanlagda area är noll,
eftersom han inte finns med alls i den tabellen.
I Städsumma går det bra, eftersom varje städare kan ha en rad där,
helt oberoende av arbetsschemat.
Uppgift 10 (3 p)
Några lösningar:
- Statiska webbsidor.
Man kopierar (förhoppningsvis inte för hand) innehållet i databasen till
HTML-kod. Eventuellt kan man ha ett program som gör detta med jämna mellanrum,
så de statiska webbsidorna hålls (ganska) uppdaterade.
- CGI-script. Ett separat program startas av webbservern,
och det programmets utmatning blir HTML-koden för en webbsida.
Det startade programmet kopplar själv upp sig mot databasen.
- En lösning med inbakade SQL-satser i HTML-koden på servern,
till exempel med ASP eller RXML.
SQL-satserna körs på servern, och deras utmatning ingår sen i HTML-koden för webbsidan,
som ersättning för SQL-satserna som stod i den ursprungliga "serverkällkoden".
Webbservern sköter uppkopplingen mot databasen.
- En klientlösning, där klienten kör något program
(till exempel i form av en Java-applet eller en DirectX-kontroll)
som självt kopplar upp sig mot databasen.
Thomas Padron-McCarthy
(Thomas.Padron-McCarthy@tech.oru.se)
11 januari 2004