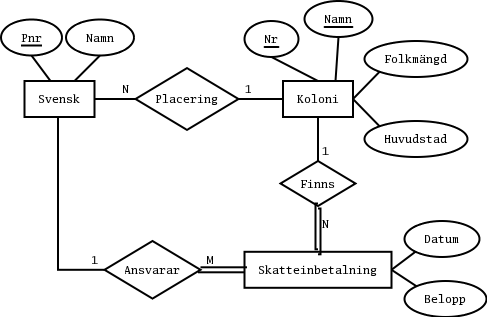
En bättre lösning med tanke på fråga 3b är att dela upp svenskarnas namn i förnamn och efternamn.
Kommentarer: Jag följer Riksskatteverkets rekommendationer (broschyr RSV 704) och lagrar personnummer med 12 siffror. Jag har lagt till en primärnyckel (id) i form av ett heltal i de tabeller som saknade en (numerisk) nyckel.create table koloni (nr integer not null, namn varchar(20) not null, folkmangd integer not null, huvudstad varchar(20) not null, primary key (nr), unique (namn)); create table svensk (id integer not null, pnr char(12) not null, namn varchar(10) not null, placering integer, primary key (id), unique (pnr), foreign key (placering) references koloni(nr)); create table skatteinbetalning (id integer not null, datum date, belopp integer, koloni integer not null, ansvarig integer not null, primary key (id), foreign key (koloni) references koloni(nr), foreign key (ansvarig) references svensk(id));
Några exempeldata:
insert into koloni values (1, 'Norge', 4593041, 'Oslo'); insert into koloni values (2, 'USA', 295734134, 'Washington'); insert into koloni values (3, 'Frankrike', 60656178, 'Paris'); insert into koloni values (4, 'Irak', 26074906, 'Bagdad'); insert into svensk values (1, '197101031499', 'Nisse', 1); insert into svensk values (2, '197201031499', 'Niklas', 1); insert into svensk values (3, '197301031499', 'Ulrik', 2); insert into svensk values (4, '197401031499', 'Ulla', 2); insert into svensk values (5, '197501031499', 'Ivar', 3); insert into svensk values (6, '197601031499', 'Inga', 3); insert into svensk values (7, '197701031499', 'Sven', null); insert into svensk values (8, '197801031499', 'Svea', null); insert into skatteinbetalning values (1, DATE'2005-06-02', 100, 1, 1); insert into skatteinbetalning values (2, DATE'2005-06-02', 100, 1, 1); insert into skatteinbetalning values (3, DATE'2005-06-02', 100, 1, 2); insert into skatteinbetalning values (4, DATE'2005-06-02', 1000, 2, 3); insert into skatteinbetalning values (5, DATE'2005-06-02', 1000, 2, 4); insert into skatteinbetalning values (6, DATE'2005-06-02', 1000, 2, 5); insert into skatteinbetalning values (7, DATE'2005-06-02', 1000, 2, 7);
select namn
from svensk
where placering = (select nr from koloni
where namn = 'Norge');
Alternativt, som en "flat" fråga:
b (1p)select svensk.namn from svensk, koloni where svensk.placering = koloni.nr and koloni.namn = 'Norge';
select namn
from koloni
where nr in (select placering from svensk
where namn like '% Svensson');
Alternativt, som en "flat" fråga:
c (2p)select distinct koloni.namn from koloni, svensk where koloni.nr = svensk.placering and svensk.namn like '% Svensson';
Här är en lösning med en nästlad fråga. Notera hur vi använder ansvarig, som är en kolumn från den yttre frågan, även i den inre frågan.select skatteinbetalning.id from skatteinbetalning, svensk where skatteinbetalning.ansvarig = svensk.id and svensk.placering <> skatteinbetalning.koloni;
select *
from skatteinbetalning
where koloni <> (select placering
from svensk
where id = ansvarig);
Notera här ett av problemen med null-värden i SQL.
En jämförelse (även <>) med null är alltid falsk,
så ingen av de ovanstående två frågorna tar med skatteinbetalningar
med ansvariga svenskar som bor kvar i Sverige,
och som därför har null som placering.
d (1p)
e (1p)select sum(belopp) from skatteinbetalning;
f (2p)create view skattesumman as select sum(belopp) as summan from skatteinbetalning;
g (2p)select koloni.namn, sum(skatteinbetalning.belopp) from skatteinbetalning, koloni where skatteinbetalning.koloni = koloni.nr group by koloni.namn;
select koloni.namn, coalesce(sum(skatteinbetalning.belopp), 0)
from skatteinbetalning right outer join koloni
on skatteinbetalning.koloni = koloni.nr
group by koloni.namn;
Ett index är en datastruktur som databashanteraren internt använder för att snabbare hitta rader i en tabell, baserat på värdet i en kolumn.
b (2p)
Dels ska databashanteraren hålla reda på att det inte blir några dubbletter i primärnyckeln, och om det inte finns något index måste den söka igenom hela tabellen för varje ny rad som läggs in. Dels är det vanligt att SQL-frågor använder sig just av primärnycklarna för att referera till rader i en tabell, och därför är det en bra chansning att skapa index på primärnycklarna.
c (3p)
Behövs:
Behövs inte:create index sp on svensk(placering); create index sa on skatteinbetalning(ansvarig); create index si on svensk(id); create index sk on skatteinbetalning(koloni);
Motivering: Man bör skapa index på de kolumner som används i sökningar, vilket ungefär betyder i jämförelser i where-villkoren. Nästlade fågor bör "flatas ut" i analysen. Till exempel är frågancreate index kr on koloni(nr); -- Behövs inte, tabellen är så liten create index km on koloni(namn); -- Behövs inte, tabellen är så liten create index sn on svensk(namn); -- Hjälper nog inte i matchningen med '% Svensson'
ekvivalent (bortsett från dubbletter i svaret) medselect A1 from A where A2 in (select B1 from B)
vilket visar att både A.A2 och B.B1 används i jämförelsen, även om det kanske inte syns så tydligt i den nästlade frågan. (Inget poängavdrag om man missat detta.)select A.A1 from A, B where A2 = B1
Om statsministern vill se hur summan hela tiden ökar, måste frågan köras ganska ofta, åtminstone någon gång per minut. Det blir dock en tung fråga för databashanteraren att köra, och den kan ta flera minuter! Kom ihåg från scenariot att regeringen hoppas på miljarder och åter miljarder skatteinbetalningar, och för att summera alla dessa miljarder och åter miljarder belopp måste man läsa allihop. Det går inte att ta några genvägar med hjälp av index.
b (2p)
En del moderna databashanterare kan automatiskt hantera materialiserde vyer, alltså vyer vars resultat lagras av databashanteraren, och sen automatiskt uppdateras när de tabeller som de grundas på ändras. Man skriver så här:
De flesta databashanterare har dock inte den funktionen än, men då kan man själv skapa en materialiserd vy med hjälp av en tabell, där man lagrar det önskade resultatet, och sen använda triggers (även kallade aktiva regler) för att hålla den tabellen aktuell när de tabeller som den grundas på ändras.create materialized view skattesumman as select sum(belopp) as summan from skatteinbetalning;
Ytterligare en lösning är att det (eller de) tillämpningsprogram som uppdaterar tabellen skatteinbetalning också uppdaterar summan, och därigenom håller vyn uppdaterad. (Det är dock en lösning som kan vara både osäker och svårhanterlig.)
En lösning är, som vanligt i sådana fall, att dela upp tabellen i flera. Man kan lägga den information om en bil som inte ändras med tiden i en tabell, som då inte behöver några giltighetstidskolumner. Den information som ändras (färg och ägare) läggs i en annan tabell, som då måste ha giltighetstidskolumner. Så här:
Permanent
| Id | Regnr | Märke | Modell | Årsmodell |
|---|---|---|---|---|
| 1 | RFN 540 | Renault | Scenic | 1999 |
| 2 | WRG 201 | Saab | 9-5 | 2005 |
| 3 | MOS 118 | Saab | 900 | 1995 |
Variabelt
| Id | Färg | Ägare | GällerFrån | GällerTill |
|---|---|---|---|---|
| 1 | Röd | 586744-1990 | 2000-03-20 | 2000-04-09 |
| 1 | Röd | 631211-1658 | 2000-04-10 | null |
| 2 | Svart | 271001-2240 | 2005-06-02 | null |
| 3 | Röd | 581012-3345 | 1995-02-18 | 2002-05-18 |
| 3 | Röd | 700222-2219 | 2002-05-19 | 2002-11-01 |
| 3 | Blå | 700222-2219 | 2002-11-02 | 2004-12-10 |
| 3 | Blå | 740119-2255 | 2004-02-11 | null |
Det beror dock på tillämpningen om det här är en bra lösning. Måste man hålla reda på även i Permanent-tabellen när uppgifterna gäller? (Bil nummer 1 fanns ju till exempel inte alls före 2000-03-20.)
En alternativ lösning är att ha en snapshot-tabell, och sen en annan tabell med historiska data.
Överkurs:
Ett annat problem är att referensintegritet kan bli svår att upprätthålla. Om en annan tabell ska referera till bilar, så är det inte bara att referera till id-numret eller registreringsnumret. En rad med rätt id-nummer eller registreringsnummer kan ju vara en "gammal" rad, som inte gäller längre.
Extra krångligt blir det om även den refererade tabellen innehåller historiska data med giltighetstider. Då måste man, på ett väldigt krångligt sätt, kontrollera att giltighetstiderna i de båda tabellerna stämmer överens med varandra.
Ytterligare en svårighet med integritetsvillkor är att hålla ordning på GällerFrån och GällerTill, så att man inte råkar få överlappande, felvända eller glappande tidsintervall.
create table Organism
(nummer integer not null,
namn varchar(10) not null,
"uppäten_av" integer,
primary key (nummer),
unique (namn));
create table Djur
(nummer integer not null,
primary key (nummer),
foreign key (nummer) references Organism(nummer));
alter table Organism
add constraint atande foreign key ("uppäten_av") references Djur(nummer);
create table "Växt"
(nummer integer not null,
primary key (nummer),
foreign key (nummer) references Organism(nummer));
create table "Fågel"
(nummer integer not null,
flyghastighet float not null,
primary key (nummer),
foreign key (nummer) references Djur(nummer));
create table Fisk
(nummer integer not null,
antal_fenor integer not null,
primary key (nummer),
foreign key (nummer) references Djur(nummer));
create table "Däggdjur"
(nummer integer not null,
primary key (nummer),
foreign key (nummer) references Djur(nummer));
Man kan tolka formuleringarna i uppgiften som fullständigt deltagande,
alltså att (1) varje organism är antingen ett djur eller en växt,
så att det alltså inte får finnas några organismer som varken är djur eller växter,
och (2) varje djur är antingen en fågel, en fisk eller ett däggdjur.
I så fall kan man använda ett integritetsvillkor för att garantera detta.
Ytterligare integritetsvillkor kan behövas för att garantera att subklasserna är disjunkta.
SQL-standarden (och Mimer) tillåter ÅÄÖ i namn, om man sätter dem inom dubbla citationstecken.