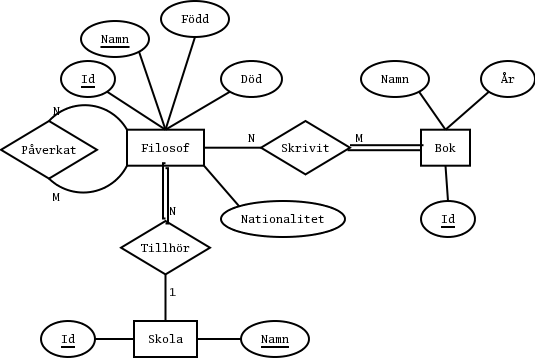
För att underlätta det fortsatta arbetet med databasen har jag också skapat id-nummer för de övriga entitetstyperna. Det är bra att göra så, eftersom entitetstyperna Filosof och Skola annars får långa textfält som nyckel, men det går också lika bra att skapa dessa id-nummer i samband med att man gör översättningen till tabeller.
Filosof(Id, Namn, Född, Död, Nationalitet, TillhörSkola)
Skola(Id, Namn)
Bok(Id, Namn, Utgivningsår)
Skrivit(Författare, Bok)
Påverkat(PåvrkandeFilosof, PåverkadFilosof)
Referensattribut:
Det kan vara praktiskt att införa databasinterna id-nummer även i tabellerna Skrivit och Påverkat.
SQL-kommandon för att provköra i Mimer:
create unique sequence SkolIdSekvens;
create table Skola
(Id integer not null primary key default next_value of SkolIdSekvens,
Namn char(6) not null unique);
create unique sequence FilosofIdSekvens;
create table Filosof
(Id integer not null primary key default next_value of FilosofIdSekvens,
Namn char(6) not null unique,
Fodd integer not null,
Dod integer,
TillhorSkola integer not null references Skola(Id));
-- Jag glömde visst nationaliteten.
create unique sequence BokIdSekvens;
create table Bok
(Id integer not null primary key default next_value of BokIdSekvens,
Namn char(6) not null,
Utgivningsar integer not null);
create unique sequence SkrivitIdSekvens;
create table Skrivit
(Id integer not null primary key default next_value of SkrivitIdSekvens,
Forfattare integer not null references Filosof(Id),
Bok integer not null references Bok(Id),
unique (Forfattare, Bok));
create unique sequence PaverkatIdSekvens;
create table Paverkat
(Id integer not null primary key default next_value of PaverkatIdSekvens,
PaverkandeFilosof integer not null references Filosof(Id),
PaverkadFilosof integer not null references Filosof(Id),
unique (PaverkandeFilosof, PaverkadFilosof));
insert into Skola (Namn) values ('Pomo');
insert into Skola (Namn) values ('Rätt');
insert into Skola (Namn) values ('Fel');
insert into Filosof (Namn, Fodd, Dod, TillhorSkola)
values ('Bert', 1872, 1970, 2);
insert into Filosof (Namn, Fodd, TillhorSkola) values ('Leif', 1965, 1);
insert into Filosof (Namn, Fodd, TillhorSkola) values ('Tommy', 1964, 1);
insert into Bok (Namn, Utgivningsar) values ('TLF', 1921);
insert into Bok (Namn, Utgivningsar) values ('KLF', 1986);
insert into Skrivit (Forfattare, Bok) values (1, 1);
insert into Skrivit (Forfattare, Bok) values (2, 1);
insert into Skrivit (Forfattare, Bok) values (2, 2);
insert into Paverkat (PaverkandeFilosof, PaverkadFilosof) values (1, 2);
insert into Paverkat (PaverkandeFilosof, PaverkadFilosof) values (1, 3);
För att rensa:
drop table filosof cascade; drop table skola cascade; drop table bok cascade; drop table paverkat cascade; drop table skrivit cascade; drop sequence SkolIdSekvens; drop sequence filosofIdSekvens; drop sequence bokIdSekvens; drop sequence paverkatIdSekvens; drop sequence skrivitIdSekvens;
select Filosof.Namn from Filosof, Skola where Filosof.TillhorSkola = Skola.Id and Skola.Namn = 'Postmodernism';
b (1p)
select Bok.Id, Bok.Namn from Filosof, Skrivit, Bok where Filosof.Namn = 'Bertrand Russell' and Filosof.Id = Skrivit.Forfattare and Skrivit.Bok = Bok.Id;
c (1p)
select Namn from Filosof where Id in (select PaverkandeFilosof from Paverkat);
d (1p)
select Namn from Filosof where Id not in (select PaverkandeFilosof from Paverkat);
e (2p)
select master.Namn, student.Namn from Filosof as master, Filosof as student, Paverkat where master.Id = Paverkat.PaverkandeFilosof and student.Id = Paverkat.PaverkadFilosof and master.Fodd > student.Dod;
f (2p)
select Skola.Namn, count(*) from Skola, Filosof where Skola.Id = Filosof.TillhorSkola group by Skola.Namn;
Det stod inget om att skolor som inte innehåller några filosofer alls måste vara med. I så fall skulle man behöva använda en yttre join:
select Skola.Namn, count(Filosof.Id) as AntalFilosofer from Skola left outer join Filosof on Skola.Id = Filosof.TillhorSkola group by Skola.Namn;
g (4p)
create view AntalPaverkade(PaverkandeFilosof, Antal)
as select PaverkandeFilosof, count(*)
from Paverkat
group by PaverkandeFilosof;
select Namn
from Filosof
where Id in (select PaverkandeFilosof
from AntalPaverkade
where Antal = (select max(Antal)
from AntalPaverkade));
Vi förutsätter att åtminstone någon filosof påverkat någon annan, så att det största antalet påverkningar inte är noll. Annars hade det behövts en yttre join i vyn för att få med någon filosof i svaret.
Skapa index på:
Fel svar:
b) (1p)
Ett index är en datastruktur som gör att det går snabbt att hitta rader i en tabell om man känner till värdet på den indexerade kolumnen.
| Nummer | Namn |
|---|---|
| 1 | Kantarell |
Fråga 2:
| Nummer | Namn |
|---|---|
| 1 | Kantarell |
| 2 | Flugsvamp |
Fråga 3:
| Nummer | Namn |
|---|---|
| 1 | Kantarell |
| 2 | Flugsvamp |
| 3 | Torsksopp |
Fråga 4:
| Nummer | Namn |
|---|---|
| 1 | Kantarell |
| 2 | Flugsvamp |
| 3 | Torsksopp |
| 4 | Slasktratt |
Fråga 5:
| Nummer | Namn |
|---|---|
| 1 | Kantarell |
| 2 | Flugsvamp |
| 3 | Torsksopp |
b) 2p)
För att separera nivåerna från varandra, så att man kan göra ändringar på en nivå utan att de andra nivåerna påverkas:
Första normalformen föreskriver enkla, odelbara värden, eller annorlunda uttryckt "högst ett värde i varje ruta". Här har jag stoppat in en hel lista med värden i samma ruta.
b) (1p)
Ingen av dessa. De höge normalformerna lägger var och en på ytterligare krav, som tabellen måste uppfylla. 2NF förutsätter 1NF, och lägger sen på ytterligare krav. 3NF förutsätter 2NF, och lägger sen på ytterligare krav. BCNF förutsätter 3NF, och lägger sen på ytterligare krav.
c) (2p)
Primärnycklarna är understrukna:
Referensattribut:
Med exempeldata
Program
|
Visning
|
d) (1p)
Båda tabellerna innehåller nu endast enkla, atomära värden. Alla fullständiga funktionella beroenden går från en kandidatnyckel (Id -> Kanal, Id -> Namn, Id -> Viktighet).
Ger användaren olle rätt att göra sökningar i tabellen Filosof, och att lägga till rader i den tabellen, men inte att ta bort eller ändra rader.grant select, insert on Filosof to olle;
Nu har olle även rätt att ändra existerande rader, men fortfarande inte att ta bort rader.grant update on Filosof to olle;
Nu har olle inte längre rätt att ta lägga till nya rader, men han kan fortfarande både söka i tabellen och ändra existerande rader.revoke insert on Filosof from olle;
b) (2p)
Nu har Olle rätt att söka bland de filosofer som är döda, men inte bland de levande.create view DodaFilosofer as select * from Filosof where Dod is not null; grant select on DodaFilosofer to olle;
Nu kan Olle dessutom ta bort döda filosofer ur vyn DodaFilosofer, och därigenom ur tabellen Filosof. Han kan dock varken se eller ta bort levande filosofer.grant select on DodaFilosofer to olle;