Observera att detta är förslag på lösningar. Det kan finnas andra lösningar som också är korrekta, och det kan hända att en del av lösningarna är mer omfattande än vad som krävs för full poäng på uppgiften.
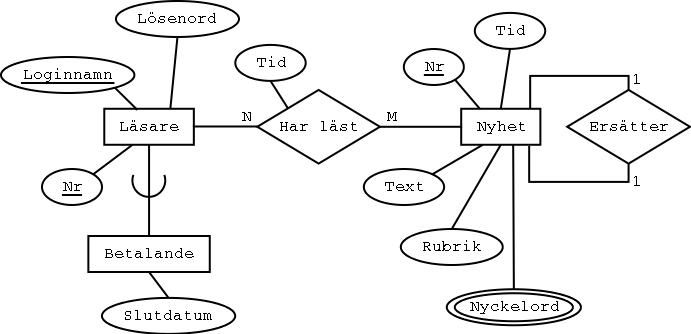
Om man vill kan man i stället göra en särskild entitetstyp Nyckelord, som har ett många-till-många-samband med Nyhet. Även en svag entitetstyp går att använda.
create table Lasare (Nr integer, Loginnamn varchar(8), Losenord varchar(8), primary key (Nr)); create table Betalande (Nr integer, Slutdatum date, primary key (Nr), foreign key (Nr) references Lasare(Nr)); create table Nyhet (Nr integer, Tid date, Rubrik varchar(100), Text varchar(2000), Ersatter integer, primary key (Nr), foreign key (Ersatter) references Nyhet(Nr)); create table HarLast (Lasare integer, Nyhet integer, primary key (Lasare, Nyhet), foreign key (Lasare) references Lasare(Nr), foreign key (Nyhet) references Nyhet(Nr)); create table Nyckelord (Nyhet integer, Ord varchar (20), primary key(Nyhet, Ord), foreign key (Nyhet) references Nyhet(Nr));
Kommentar: En del verkar ha fått för sig att alla jämförelser av textsträngar ska göras med like i stället för =. Det är fel. Like används bara vid mönstermatchning. Jag har dock inte dragit några poäng för det, för det fungerar lika bra med like - så länge man inte vill jämföra med tecknen % och _. Det är ju de som används som jokertecken av like.select Text from Nyhet where Rubrik = 'Norge vann VM';
b) (2p) Vilka rubriker har de nyheter som läsaren med loginnamnet Bengt har läst?
Eller:select Rubrik from Nyhet, HarLast, Lasare where Nyhet.Nr = HarLast.Nyhet and HarLast.Lasare = Lasare.Nr and Lasare.Loginnamn = 'Bengt';
select Rubrik
from Nyhet
where Nr in (select Nyhet
from HarLast
where Lasare in (select Nr
from Lasare
where Loginnamn = 'Bengt'));
Eller, om man av någon anledning råkar gilla explicita joinar:
Eller "åt andra hållet":select Rubrik from (Nyhet join HarLast on Nyhet.Nr = HarLast.Nyhet) join Lasare on HarLast.Lasare = Lasare.Nr where Lasare.Loginnamn = 'Bengt';
c) (2p) Vilka rubriker har de nyheter som läsaren med loginnamnet Bengt inte har läst?select Rubrik from (Lasare join HarLast on Lasare.Nr = HarLast.Lasare) join Nyhet on HarLast.Nyhet = Nyhet.Nr where Lasare.Loginnamn = 'Bengt';
select Rubrik
from Nyhet
where Nr not in (select Nyhet
from HarLast
where Lasare in (select Nr
from Lasare
where Loginnamn = 'Bengt'));
Kommentar:
En del har använt <> i stället för not in. Det ger helt fel svar.
d) (2p) Hur många läsare har läst nyheten som har rubriken Norge vann VM?
Eller:select count(Lasare.Nr) from Lasare, HarLast, Nyhet where Lasare.Nr = HarLast.Lasare and HarLast.Nyhet = Nyhet.Nr and Nyhet.Rubrik = 'Norge vann VM';
select count(*)
from Lasare
where Nr in (select Lasare
from HarLast
where Nyhet = (select Nr
from Nyhet
where Rubrik = 'Norge vann VM'));
Egentligen behöver man inte titta i läsartabellen:
e) (3p) Vad är rubriken på den nyhet som lästs av flest läsare?select count(*) from HarLast, Nyhet where HarLast.Nyhet = Nyhet.Nr and Nyhet.Rubrik = 'Norge vann VM';
create view AntalLasare as
select Nyhet, count(*) as Antal
from HarLast
group by Nyhet;
select Rubrik
from Nyhet
where Nr in (select Nyhet
from AntalLasare
where Antal = (select max(Antal) from AntalLasare));
Dessa kolumner används i join (när man kopplar ihop tabeller) och select (när man väljer rader i en tabell baserat på värdet i en eller flera kolumner). De är inte heller breda textkolumner, och de har inte dålig selektivitet.
Kommentarer:
Nästan rätt, utom att (1) en tabell består av en eller flera kolumner, inte två eller flera, och (2) man kan använda flera kolumner som sammansatt nyckel, och (3) man kan dessutom ha flera olika kandidatnycklar i en tabell. Det är också lite oklart vad de menar med att "samma nyckel kan förekomma i flera tabeller". Om de menar att en nyckel i en tabell kan förekomma som referensattribut i en annan tabell, utan att nödvändigtvis vara nyckel i den tabellen, är det rätt.
Dessutom vill den där järnhandeln nog hellre joina kundregistret med försäljningsregistret!
b) databas (1p)
Rätt. Det är dock lite oklart vad de menar med att "skilt från".
c) atomärt värde (2p)
Helt fel. Atomära värden har inte att göra med vad som går att räkna fram utgående från andra värden, utan om att de atomära värdena inte kan delas upp och delarna sen användas i sökningar. Ett heltal i en databas är ett atomärt värde, oavsett om det kan räknas ut utifrån andra värden eller inte, men en lista av heltal, där man kan söka efter eller jämföra med de enskilda talen i listan, är inte att atomärt värde.
d) referentiell integritet (2p)
Åtminstone i akademiska sammanhang brukar man oftare säga referensintegritet på svenska. Förklaringen är rätt så till vida att det har med konsekvens och motsägelsefrihet att göra, men annars är det fel. Det som beskrivs i förklaringen är någon sorts dubbelriktade samband, men referensintegritet handlar helt enkelt om att de värden som används i ett referensattribut också ska finnas i den tabell som referensattributet refererar till. Om det till exempel står i tabellen Anställd att Sven arbetar på avdelning 7, så ska det också finnas en avdelning med nummer 7 i tabellen Avdelning.
e) trigger (1p)
Rätt. (Man brukar inte använda triggers till att upprätthålla referensintegritet, men den sortens dubbelriktade samband som Computer Sweden tror är referensintegritet kan man behöva triggers till.)
Kommentar: Många har anmärkt på påståendet att en trigger skulle kunna "göra vad som helst - utlösa larm, skicka meddelanden om överskriden kreditgräns eller starta andra program". Om den kan detta är förstås beroende på om databashanteraren har sådana funktioner. Det finns det databashanterare som har.
d)
SQLBindCol används för att binda kolumner i resultatet från en SQL-fråga till variabler i C-programmet, så att man kan överföra data från databasen till C-programmet. SQLBindParameter används för att binda delar i en SQL-fråga, markerade med frågetecken, till variabler i C-programmet, så att man kan överföra data från C-programmet till databasen.
e)
SQLExecPrepare förbereder körningen av frågan på databasservern, med parsning av frågans text och med optimering, medan SQLExecute sedan verkligen kör frågan. Fördelen är att man kan förbereda en fråga en gång, och sen köra den många gånger med olika parametrar. För att spara exekveringstid bör en fråga som ska köras inuti en loop därför delas upp, så att man gör SQLExecPrepare före loopen, och sen bara SQLExecute inuti loopen.
Antag att vi ofta vill summera alla lönerna i employee-tabellen:
Vi skapar en liten tabell och lagrar summan där:select sum(salary) as salsum from employee;
Lönesumman kan ändras om man lägger till, tar bort eller ändrar anställda. Därför måste vi skapa tre aktiva regler för employee-tabellen, en för insert, en för delete och en för update.create table salsum (salsum integer); insert into salsum (salsum) select sum(salary) from employee; select salsum from salsum; +----------------------+ | SALSUM | +----------------------+ | 296688 | +----------------------+ 1 rows returned
Om vi nöjer oss med att det bara fungerar att lägga till, ta bort och ändra en rad i taget, blir det så här, med Mimer-syntax:
@
create trigger emp_insert after insert on employee
referencing new table as n
for each statement
begin atomic
declare newsal integer;
select salary into newsal from n;
update salsum set salsum = salsum + newsal;
end
@
@
create trigger emp_delete after delete on employee
referencing old table as o
for each statement
begin atomic
declare oldsal integer;
select salary into oldsal from o;
update salsum set salsum = salsum - oldsal;
end
@
@
create trigger emp_update after update on employee
referencing old table as o new table as n
for each statement
begin atomic
declare oldsal integer;
declare newsal integer;
select salary into oldsal from o;
select salary into newsal from n;
update salsum set salsum = salsum - oldsal + newsal;
end
@
CGI-program kan vara långsamma därför att om en webbsida ska genereras av ett CGI-program, så måste programmet startas och köras varje gång någon vill titta på den webbsidan. Att starta ett program tar på de flesta system mycket lång tid, jämfört med att göra saker i programmet när det väl har startats.
På en databasbaserade webbplats kan CGI-program vara extra långsamma, eftersom CGI-programmet inte bara måste startas, utan det måste dessutom koppla upp sig mot databashanteraren och logga in. Detta kan ta lång tid, jämfört med att bara köra en SQL-fråga.