Det här är hemtentan i kursen Databasteknik II.
Den ska lämnas in senast lördag 30 augusti 2014.
Ansvarig lärare är
Thomas Padron-McCarthy
(thomas.padron-mccarthy@oru.se)
telefon 070-73 47 013.
Instruktioner
-
Lös uppgifterna och skicka sen in svaren till mig
(thomas.padron-mccarthy@oru.se)
senast lördag 30 augusti 2014.
Sista inlämningsdagen håller på hela dagen, så senaste inlämningstid är vid midnatt.
-
Uppgiften ska lösas enskilt, dvs inga grupper av två eller flera studenter.
-
Man måste ha lämnat in labbarna innan man gör tentan.
Det är inte nödvändigt att de är rättade eller godkända,
men de måste vara inlämnade.
-
För att få godkänt resultat den här hemtentan
ska man ha besvarat frågorna på ett sätt som visar att man läst och förstått (delar av) kurslitteraturen.
-
Jag räknar ungefär så här:
Varje uppgift blir antingen godkänd med 4 eller 5 poäng, eller underkänd med noll poäng.
Inga halv- eller enpoängare för att man försökt lösa en uppgift och kanske lyckats få med någon detalj som är rätt.
För godkänt på tentan krävs minst 5 godkända uppgifter,
vilket motsvarar en godkänt-gräns på 20 poäng av maximalt 30.
Vissa kompletteringar i efterhand kan tillåtas.
-
Godkänt resultat på den här hemtentan ger betyget G på teoridelen av kursen.
För att få hela kursen godkänd krävs dessutom godkända inlämningsuppgifter.
-
Du får använda dator, böcker och vilka andra hjälpmedel som helst, men
du får inte samarbeta eller fråga någon (utom mig).
Exempelvis är det tillåtet att söka och läsa på webbplatser som Stack Overflow,
men inte att ställa egna frågor.
-
Antaganden utöver de som står i uppgifterna måste anges. Gjorda
antaganden får inte förändra den givna uppgiften.
-
Oklara formuleringar kommer att misstolkas.
-
Skriv gärna förklaringar om hur du tänkt.
Även ett svar som är fel kan ge poäng,
om det finns med en förklaring som visar att huvudtankarna var rätt.
-
Om du behöver fråga något, så kontakta gärna mig.
Om det är bråttom sig är det nog bäst att ringa eller SMS:a
(se mobilnumret ovan),
för det är inte säkert att jag sitter vid datorn, särskilt på helgerna.
-
Undvik Word-dokument. PDF eller text fungerar bättre.
-
Om du inte senast under måndagen får e-post från mig med en bekräftelse
på att du skickat in något,
bör du kontakta mig, enklast genom att ringa eller SMS:a mig
(ifall det är e-posten som inte fungerar).
Scenario
Det här är samma scenario som på förra tentan,
nämligen att vi lagrar en skog.
En skog, i datasammanhang, är en mängd av träd.
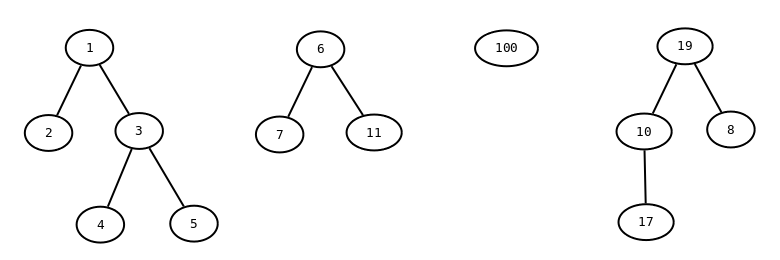
Träden består av noder och bågar, och vi kan beskriva dem med en tabell:
| Noder |
|---|
| Nummer | Foralder |
|---|
| 1 | null |
| 2 | 1 |
| 3 | 1 |
| 4 | 3 |
| 5 | 3 |
| 6 | null |
| 7 | 6 |
| 8 | 19 |
| 10 | 19 |
| 11 | 6 |
| 17 | 10 |
| 19 | null |
| 100 | null |
Varje nod har alltså ett unikt nummer, och högst en annan nod som förälder.
Exemplet ovan innehåller tretton noder och fyra träd.
I schemat skogen i databasen dbk på Mimer-servern basen.oru.se
finns ett större exempel, med ovanstående noder plus ytterligare en miljon:
SQL>select count(*) from skogen.noder;
===========
1000013
1 row found
Alternativt kan man själv skapa och fylla databasen med hjälp av filen
skapa-skogen.txt (64 megabyte)
som innehåller SQL-kommandon för att skapa tabellen och fylla den med data.
Den kan laddas ner här som en Zip-fil:
skapa-skogen.zip (6 megabyte).
Om man använder Mimer och Batch SQL kan filen läsas med Batch SQL:s kommando read, till exempel så här:
read all input from 'C:\Documents and Settings\tpy\Skrivbord\skapa-skogen.txt';
Dessutom rekommenderas kommandot update statistics.
Uppgift 1 (5 p)
Skriv ett program som kopplar upp sig mot databasen.
Programmet ska fråga efter numret på en nod,
och sen skriva ut alla noder i subträdet under den noden.
Exempel:
- Nod nummer 3 ska ge noderna 4 och 5 som svar.
- Nod nummer 4 ska inte ge några noder alls som svar.
- Nod nummer 6 ska ge noderna 7 och 11 som svar.
- Nod nummer 100 ska inte ge några noder alls som svar.
- I det större exemplet ska nod nummer 1500000 ge nod nummer 1913791 som svar.
- I det större exemplet ska nod nummer 1100000 ge noderna
1192188,
1963529,
1213436,
1274395,
1299314,
1436452 och
1711955 som svar
(Man kan också välja att ha med subträdets rotnod i utskriften,
om det ger enklare kod.)
Programmet ska använda sig av någon form av databasåtkomst inifrån programmet,
till exempel med JDBC från ett Java-program,
ODBC eller ESQL från ett C-program,
ADO.NET,
eller liknande.
Uppgift 2 (5 p)
När jag kör följande två SQL-frågor i exempeldatabasen
med drygt en miljon rader i tabellen,
går max-frågan mycket fortare än count-frågan:
select max(nummer) from skogen.noder;
select count(*) from skogen.noder;
Vad kan det bero på att det blir så?
Man tycker ju att det tvärtom borde gå fortare att bara räkna raderna än att gå igenom dem för att hitta max-värdet?
Uppgift 3 (5 p)
Vi använder följande SQL-fråga för att få fram barnen till nod nummer 1000000:
select * from skogen.noder where foralder = 1000000;
Det finns 1000013 rader i tabellen.
Gör rimliga antaganden om blockstorlek med mera, och räkna ut hur lång tid det tar att köra frågan
i en normal relationsdatabas, i följande olika fall:
a) Om det inte finns några index alls på tabellen.
b) Om det finns ett primärindex av typen B+-träd på kolumnen nummer.
c) Om det finns ett sekundärindex av typen B+-träd på kolumnen foralder.
d) Om det finns två olika index av typen B+-träd på kolumnerna nummer och foralder.
Det är ett primärindex respektive ett sekundärindex.
e) Om det finns ett sammansatt index av typen B+-träd på kolumnerna nummer och foralder.
Det är ett primärindex.
(Meningen är alltså att man ska resonera och räkna sig fram till svaret, inte att man ska provköra.)
Uppgift 4 (5 p)
Vi vill få fram vilka noder i andra halvan av tabellen som är barnbarn till nod nummer 1000000:
select barnbarn.nummer from skogen.noder as mormor, skogen.noder as barn, skogen.noder as barnbarn
where mormor.nummer = 1000000
and barn.foralder = mormor.nummer
and barnbarn.foralder = barn.nummer
and barnbarn.nummer > 1500000
a)
Ange den systematiska översättningen av frågan,
även kallad kanonisk form,
till relationsalgebra.
(Det är alltså den o-optimerade formen.)
Skriv den som ett relationsalgebrauttryck.
b)
Rita upp samma relationsalgebrauttryck som ett träd.
c)
Visa hur en heuristisk frågeoptimerare,
som inte tar hänsyn till datamängder eller lagringsstrukturer,
optimerar den kanoniska formen.
Visa både vilka olika optimeringar som görs, och vad slutresultatet blir.
d) En heuristisk optimerare följer några enkla regler för vilka transformationer den ska göra på relationsalgebran.
Finns det några uppenbara problem (dvs långsamma val) med det färdiga, optimerade trädet i c-uppgiften ovan,
om man jämför med hur en riktig databashanterare som Mimer faktiskt skulle köra frågan?
Uppgift 5 (5 p)
I en databashanterare körs två olika transaktioner (T1 och T2)
enligt följande tidsschema.
Transaktionerna arbetar med tre olika dataobjekt (A, B och C).
| Tid | T1 | T2 |
|---|
| 1 | Start | |
| 2 | Läs(A) | |
| 3 | | Start |
| 4 | | Läs(A) |
| 5 | Skriv(B) | |
| 6 | | Läs(B) |
| 7 | | Skriv(C) |
| 8 | Commit | |
| 9 | | Commit |
I tidsschemat ovan användes ingen metod för att hålla transaktionerna isolerade från varandra.
a)
Är tidsschemat serialiserbart? Motivera svaret!
b)
Visa hur tidsschemat ovan skulle förändras om man använder
strikt tvåfaslåsning med läs- och skrivlås,
där inga lås (inte ens läslås) släpps förrän efter att transaktionen har committat.
Visa också låsen och hur de låses och låses upp.
c)
Visa hur det ursprungliga tidsschemat skulle förändras om man använder
tidsstämpelmetoden, med lästids- och skrivtidsstämplar.
Visa också tidsstämplarna.
Uppgift 6 (5 p)
På kursens webbplats finns en beskrivning av kursens innehåll
(http://basen.oru.se/kurser/db2/2013-2014-p34/innehall.html).
Den ser ut ungefär så här, om man först stryker de ämnen som frågorna ovan redan tar upp:
-
Tid i databaser, temporala databaser
-
Objektorienterade och objektrelationella databaser
-
Datautvinning ("data mining") och datalager ("data warehouses")
-
Distribuerade databaser, multidatabaser
-
Legacy databases, mediatorer
-
SQL, NoSQL och NewSQL
-
Object-relational mapping
Välj ett av dessa sju ämnen,
och skriv en introduktion om det.
Målgruppen är någon som kan "datorer" och programmering,
och som gått en grundkurs om databaser.
Det kan vara lämpligt med en eller kanske två A4-sidor text
för själva beskrivningen.
Men ha gärna med förklarande exempel,
och i så fall kan det gå åt ytterligare en eller flera sidor för exemplen.
Använd gärna källor, men:
- Skriv med egna ord.
- Ange vilka källor du använt.
Thomas Padron-McCarthy
(thomas.padron-mccarthy@oru.se),
22 augusti 2014