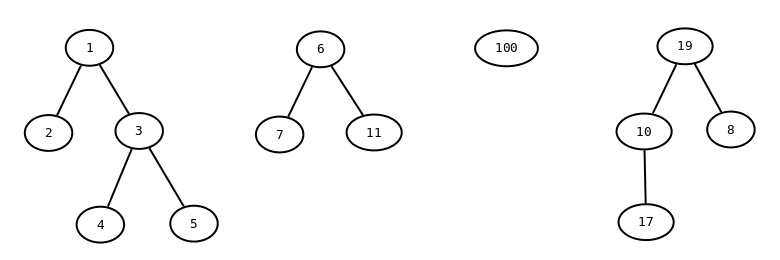
Träden består av noder och bågar, och vi kan beskriva dem med en tabell:
| Noder | ||||
|---|---|---|---|---|
| Nummer | Foralder | |||
| 1 | null | |||
| 2 | 1 | |||
| 3 | 1 | |||
| 4 | 3 | |||
| 5 | 3 | |||
| 6 | null | |||
| 7 | 6 | |||
| 8 | 19 | |||
| 10 | 19 | |||
| 11 | 6 | |||
| 17 | 10 | |||
| 19 | null | |||
| 100 | null | |||
Varje nod har alltså ett unikt nummer, och högst en annan nod som förälder.
Exemplet ovan innehåller tretton noder och fyra träd. I schemat skogen i databasen dbk på Mimer-servern basen.oru.se finns ett större exempel, med ovanstående noder plus ytterligare en miljon:
SQL>select count(*) from skogen.noder;
===========
1000013
1 row found
Alternativt kan man själv skapa och fylla databasen med hjälp av filen skapa-skogen.txt (64 megabyte) som innehåller SQL-kommandon för att skapa tabellen och fylla den med data. Den kan laddas ner här som en Zip-fil: skapa-skogen.zip (6 megabyte). Om man använder Mimer och Batch SQL kan filen läsas med Batch SQL:s kommando read, till exempel så här:
Dessutom rekommenderas kommandot update statistics.read all input from 'C:\Documents and Settings\tpy\Skrivbord\skapa-skogen.txt';
Exempel:
Programmet ska använda sig av någon form av databasåtkomst inifrån programmet, till exempel med JDBC från ett Java-program, ODBC eller ESQL från ett C-program, ADO.NET, eller liknande.
select n1.nummer from noder as n1, noder as n2, noder as n3 where n1.foralder = n2.nummer and n2.foralder = n3.nummer and n3.nummer < 1000;
(Det är nod nummer 4, 5 och 17.)
a) Ange den systematiska översättningen av frågan, även kallad kanonsik form, till relationsalgebra. (Det är alltså den o-optimerade formen.) Skriv den som ett relationsalgebrauttryck.
b) Rita upp samma relationsalgebrauttryck som ett träd.
c) Vi antar att databashanteraren arbetar internt med relationsalgebra. Förklara skillnaden mellan att köra relationsalgebrauttrycket ovan med materialiserade mellanresultat och med strömmade mellanresultat ("pipe-lining").
d) Visa hur en heuristisk frågeoptimerare, som inte tar hänsyn till datamängder eller lagringsstrukturer, optimerar den kanoniska formen. Visa både vilka olika optimeringar som görs, och vad slutresultatet blir.
e) Vilka saker finns i det optimerade uttrycket som en kostnadsbaserad frågeoptimerare (eller en heuristisk optimerare som bryr sig om datamängder och lagringsstrukturer) skulle kunna gjort bättre? (Alternativt, ifall det redan råkat bli helt perfekt, vad kunde den heuristiska optimeraren ha missat?)
Med kommandot SET EXPLAIN ON i Mimer kan man visa exekveringsplaner. Här är två sätt att visa vilka noder i exempeltabellen som har någon av noderna i det lilla exemplet som förälder.
SQL>set explain on;
SQL>select * from skogen.noder where foralder < 1000;
Start of explain result
L1:
Index scan using index SKOGEN.FORALDER, end of table goto end
compare, no hit goto L1
Record found, goto L1
end:
End of explain result
NUMMER FORALDER
=========== ===========
2 1
3 1
4 3
5 3
7 6
11 6
17 10
8 19
10 19
9 rows found
SQL>select * from skogen.noder where foralder < 1000000;
Start of explain result
L1:
Sequential read SKOGEN.NODER, end of table goto end
compare, no hit goto L1
Record found, goto L1
end:
End of explain result
NUMMER FORALDER
=========== ===========
2 1
3 1
4 3
5 3
7 6
8 19
10 19
11 6
17 10
9 rows found
SQL>
Frågorna ger samma svar, men den andra optimeras till en annan exekveringsplan,
och den tar längre tid att köra.
Förklara varför Mimer väljer olika exekveringsplaner!
Nu ska vi länka in det fjärde trädet från exemplet ovan, det med nod nummer 19 som rotnod, under ett av de andra träden. Vi startar en transaktion, som vi kan kalla transaktion A:
Strax efteråt startar någon annan en annan transaktion, transaktion B:start transaction; select * from Noder where nummer = 19;
Därefter fortsätter transaktion A:start transaction; select * from Noder where nummer = 19; update Noder set foralder = 11 where nummer = 19;
Transaktion B committar:update Noder set foralder = 5 where nummer = 19;
Transaktion A committar:commit;
commit;
Man kan också skriva upp inmatningarna till de två SQL-sessionerna så här:
| Step | Transaktion A | Transaktion B |
|---|---|---|
| 1 | start transaction; select * from Noder where nummer = 19; |
|
| 2 | start transaction; select * from Noder where nummer = 19; update Noder set foralder = 11 where nummer = 19; | |
| 3 | update Noder set foralder = 5 where nummer = 19; |
|
| 4 | commit; | |
| 5 | commit; |
Vad händer? Visa hur låsen sätts och ändras, om någon av transaktionerna väntar, och vad resultatet blir. Avbryts någon transaktion? Kommer ändringar att rullas tillbaka?
Visa hur man kan använda tidsdimensionerna giltighetstid och transaktionstid i den här databasen för att lagra olika versioner av data. Hur behöver man ändra tabellerna? Blir det några särskilda problem, till exempel med integritetsvillkor? Finns det någon extra funktionalitet som det vore bekvämt att ha i databashanteraren?
Hade en temporal databas med transaktionstid hjälpt mot problemen ovan med ändringar i databasen? Visa hur, eller förklara varför det inte hade hjälpt.
a) Hade det varit bättre eller sämre att lagra den i form av en objektorienterad eller objektrelationell databas? Motivera svaret!
b) Hade det varit bättre eller sämre att inte lagra den som en databas alls, med databashanterare, utan bara med vanliga datastrukturer i ett språk som C eller Java? Motivera svaret!
c) Skogen växer från en miljon (106) till en biljon (1012) noder. Ändras svaret i delfråga b? Motivera svaret!