Databasteknik II
för D3 m fl
lördag 4 april 2009 kl 08:15 - 12:15
Gäller som tentamen för:
DT3001 Datateknik C, Databasteknik II, provkod 0100
TDD119 Databaser, fortsättningskurs, provkod 0100
| Hjälpmedel: | Miniräknare. |
| Poängkrav: |
Maximal poäng är 40.
För betyget 3 krävs 20 poäng. |
| Resultat och lösningar: | Meddelas via e-post eller på kursens hemsida, http://basen.oru.se/kurser/db2/2008-2009-p3/, senast lördag 25 april 2009. |
| Återlämning av tentor: | Efter att resultatet meddelats kan tentorna hämtas på institutionen. Man kan också få sin rättade tenta hemskickad. |
| Examinator och jourhavande: | Thomas Padron-McCarthy, telefon 070-73 47 013. |
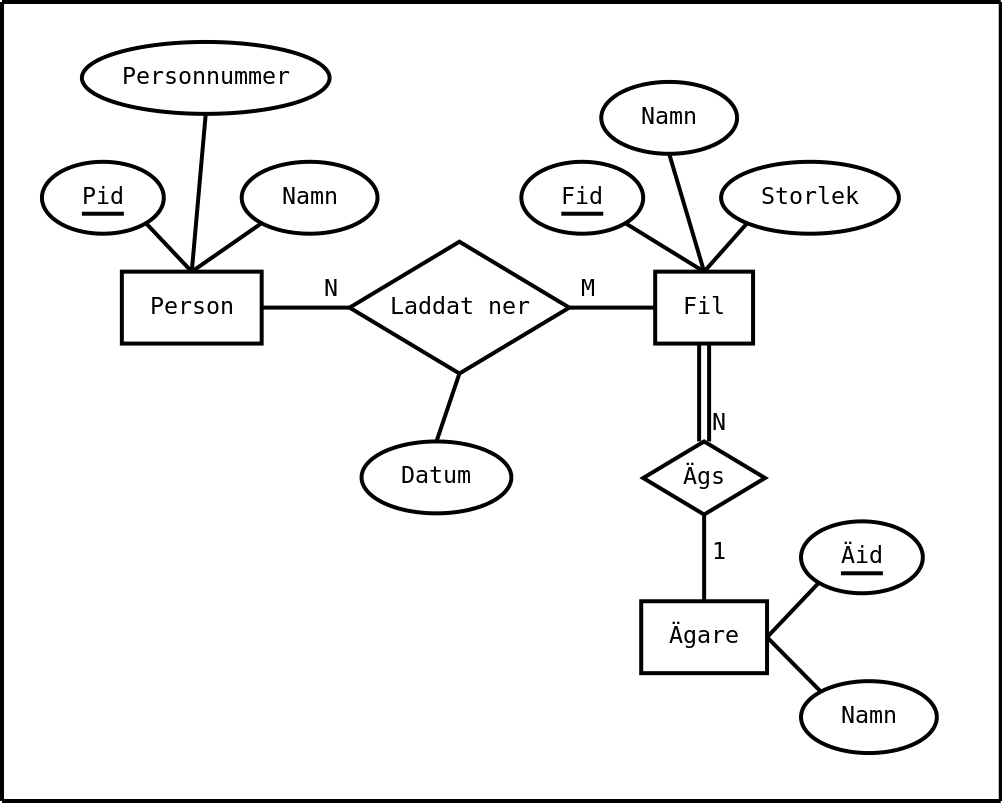
Här är en implementation av Antipiratbyråns databas i form av en relationsdatabas:
|
Tabellen Personer
10 miljoner rader |
| ||||||||||||||||||||
|
Tabellen LaddatNer
100 miljoner rader |
| ||||||||||||||||||||
|
Tabellen Filer
10 miljoner rader |
| ||||||||||||||||||||
|
Tabellen Ägare
100 rader |
|
select Personer.Personnummer, Personer.Namn from Personer, LaddatNer, Filer, "Ägare" where Personer.Pid = LaddatNer.Person and LaddatNer.Fil = Filer.Fid and Filer."Ägare" = "Ägare"."Äid" and "Ägare".Namn = 'Sony Music' and LaddatNer.Datum = '2009-04-04';
a) (2p) Ange den systematiska översättningen av SQL-frågan till relationsalgebra, även kallad kanonisk form. (Det är alltså den o-optimerade formen.) Skriv upp den som ett relationsalgebrauttryck.
b) (1p) Rita upp samma relationsalgebrauttryck som ett frågeträd.
c) (4p) Visa hur en heuristisk frågeoptimerare optimerar den kanoniska formen från frågan ovan. Visa både vilka olika optimeringar som görs, och vad slutresultatet blir.
d) (1p) Hur fungerar en kostnadsbaserad frågeoptimerare?
e) (2p) En kostnadsbaserad frågeoptimerare kan ta hänsyn till en del saker som en heuristisk frågeoptimerare normalt inte bryr sig om. Vilka? Förklara, med exempel från databasen och frågan i exemplet!
Databashanteraren arbetar med en blockstorlek på 2048 byte, och det tar i genomsnitt 10 millisekunder att hitta och läsa ett godtyckligt block från disken. Gör rimliga antaganden i övrigt (och ange dem!) och räkna sen ut hur lång tid det i genomsnitt tar att köra denna fråga, om tabellen är lagrad:select Namn from Personer where Personnummer = '081213-1658';
a) (2p) enbart med ett primärindex i form av ett B+-träd på Id
b) (2p) med ett primärindex enligt a-uppgiften, och dessutom med ett sekundärindex i form av ett B+-träd på Personnummer.
c) (2p) Antipiratbyrån kommer att arbeta mycket flitigt, och göra flera hundra sådana sökningar per sekund. Är det troligt att deras databas klarar detta? Motivera svaret!
Visa (i alla deluppgifterna) hur du räknat!
| Tid | T1 | T2 | T3 |
|---|---|---|---|
| 1 | Start | ||
| 2 | Start | ||
| 3 | Läs(Y) | ||
| 4 | Läs(Z) | ||
| 5 | Läs(X) | ||
| 6 | Start | ||
| 7 | Läs(Z) | ||
| 8 | Läs(Y) | ||
| 9 | Skriv(X) | ||
| 10 | Commit | ||
| 11 | Skriv(Y) | ||
| 12 | Skriv(Z) | ||
| 13 | Commit | ||
| 14 | Skriv(Z) | ||
| 15 | Commit |
Precis före commit-operationen på rad 13 går plötsligt strömmen.
a) (2p) Hur ser loggfilen ut då?
b) (3p) Vilka operationer kommer att utföras under recovery-processen, när databasen återstartas?
b) (1p) Och vad innebär egentligen serialiserbarhet?
c) (5p) Välj två av följande metoder för isolering av transaktioner, och visa hur tidsschemat ovan skulle förändras om respektive metod användes. (Observera: Välj alltså två av dessa metoder!)
b) (2p) Vad är ett stjärnschema, och varför använder man det?
c) (2p) Vad är en dimensionstabell, och varför uppfyller den ofta bara andra normalformen?
(Försök) ange en stor fördel med var och en av dessa, jämfört med de andra.