Databasteknik II
för D3 m fl
lördag 29 mars 2008 kl 08:00 - 12:00
Gäller som tentamen för:
DT3001 Datateknik C, Databasteknik II, provkod 0100
TDD119 Databaser, fortsättningskurs, provkod 0100
| Hjälpmedel: | Miniräknare. |
| Poängkrav: |
Maximal poäng är 42.
För betyget 3 krävs 21 poäng. |
| Resultat och lösningar: | Meddelas på kursens hemsida, http://www.aass.oru.se/~tpy/db2/2007-2008-p3/, senast lördag 19 april 2008. |
| Återlämning av tentor: | Efter att resultatet meddelats kan tentorna hämtas på institutionen. Man kan också få sin rättade tenta hemskickad. |
| Examinator och jourhavande: | Thomas Padron-McCarthy, telefon 070-73 47 013. |
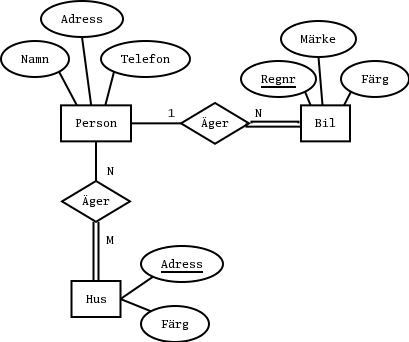
Här är en implementation av databasen i form av en relationsdatabas:
|
Tabellen Personer
(1 miljon rader) |
| |||||||||||||||||||||||||
|
Tabellen Bilar
(1 miljon rader) |
| |||||||||||||||||||||||||
|
Tabellen Hus
(100 000 rader) |
| |||||||||||||||||||||||||
|
Tabellen Husägande
(1 miljon rader) |
|
| Observera: Välj ut och besvara (högst) sju av de åtta uppgifterna. (Skulle du svara på alla åtta, räknas den med högst poäng bort.) |
a) (4p)
(Försök) ange en stor fördel med var och en av dessa, jämfört med de andra.
b) (2p)
Om du personligen skulle skriva ett tillämpningsprogram som arbetar mot databasen i scenariot ovan, vilken av dessa tekniker skulle du välja? Utgå från din egen tillgång till verktyg, och egna kunskaper inom programmeringsspråk med mera. Motivera varför du valde just den tekniken.
a) (2p)
Vad är skillnaden mellan giltighetstid och transaktionstid? Förklara, med tabellen Personer från scenariot som exempel.
b) (1p)
De flesta databashanteraren har inget inbyggt stöd för tidsdimensioner, utan om man behöver hantera tidsdimensioner måste man göra det i form av vanliga tabeller (om det nu är en relationsdatabas). Hur skulle man implementera giltighetstid i Personer-tabellen?
c) (1p)
Hur skulle man implementera transaktionstid i Personer-tabellen?
d) (2p)
Visa med exempel från scenariodatabasen vilka problem med referensintegritet som man kan få, när man lägger till tidsdimensioner.
| Tid | T1 | T2 | T3 | T4 |
|---|---|---|---|---|
| 1 | Start | |||
| 2 | Läs(X) | |||
| 3 | Skriv(X) | |||
| 4 | Commit | |||
| 5 | Start | |||
| 6 | Start | |||
| 7 | Start | |||
| 8 | Läs(X) | |||
| 9 | Läs(Y) | |||
| 10 | Läs(Z) | |||
| 11 | Läs(X) | |||
| 12 | Läs(Y) | |||
| 13 | Skriv(X) | |||
| 14 | Skriv(Y) | |||
| 15 | Commit | |||
| 16 | Commit | |||
| 17 | Skriv(Z) | |||
| 18 | Commit |
a) (2p)
Här användes ingen metod för att hålla transaktionerna isolerade från varandra. Vilket eller vilka fel kan i just det här fallet ha uppstått i databasen på grund av detta? (Förklara!)
b) (4p)
Välj någon av metoderna för isolering av transaktioner, förklara kort hur metoden fungerar, och visa hur tidsschemat ovan skulle förändras om den metoden användes.
Databasen lagras med en vanlig, diskbaserad relationsdatabashanterare på en vanlig, modern dator. Gör rimliga antaganden om blockstorlek mm (och ange dem!), och räkna sen ut hur lång tid det i genomsnitt tar att köra denna fråga, om tabellen är lagrad:select Namn, Adress from Personer where Pid = 4711;
a) utan något index (eller annan sökväg) på Pid
b) med ett primärindex i form av ett B+-träd på Pid
c) med ett sekundärindex i form av ett B+-träd på Pid
Här är en SQL-fråga som tar fram namn och adress på de personer som heter Thomas Padron-McCarthy:
Med samma antaganden om blockstorlek mm som ovan, hur lång tid tar det i genomsnitt att köra denna fråga, om tabellen är lagrad:select Namn, Adress from Personer where Namn = 'Thomas Padron-McCarthy';
d) utan något index (eller annan sökväg) på Namn
e) med ett sekundärindex i form av ett B+-träd på Namn
Ange antagandena, och visa hur du räknat!
Du ska visa den systematiska översättningen av frågan, även kallad kanonsik form, till relationsalgebra. (Det är alltså den o-optimerade formen.)select Namn, Telefon from Personer, Bilar, "Husägande", Hus where Personer.Pid = Bilar."Ägare" and Bilar."Färg" = 'Röd' and Personer.Pid = "Husägande"."Ägare" and "Husägande".Hus = Hus.Hid and Hus."Färg" = 'Blått';
a) (1p)
Skriv upp den som ett relationsalgebrauttryck.
b) (1p)
Rita upp samma relationsalgebrauttryck som ett träd.
c) (4p)
Visa hur en heuristisk frågeoptimerare, som inte tar hänsyn till datamängder eller lagringsstrukturer, optimerar den kanoniska formen från frågan ovan. Visa både vilka olika optimeringar som görs, och vad slutresultatet blir.
a) (2p)
Om en databashanterare arbetar internt med exekveringsplaner i form av relationsalgebra, hur lång tid skulle det ta att köra det o-optimerade uttrycket från frågan ovan? Vi räknar med att vi har en ganska snabb dator, med 2048 stycken dubbelkärniga 2.6 GHz-processor:

Vi räknar (förmodligen lite väl optimistiskt) med att frågan kan köras fullt parallellt på datorn, och att varje processorkärna kan hantera en rad i en relationsalgebraoperation per klockcykel. Det blir 1013 rader per sekund. Här ska vi inte bry oss om diskläsningar och datastrukturer, utan bara hur många rader som behöver behandlas, inklusive alla mellanresultat. Antalet rader i tabellerna står i scenariot.
b) (1p)
Hur lång tid tar det optimerade uttrycket att köra, med samma antaganden som i deluppgiften ovan?
c) (3p)
Vilka saker finns i det optimerade uttrycket som en kostnadsbaserad frågeoptimerare (eller en heuristisk optimerare som bryr sig om datamängder och lagringsstrukturer) skulle kunna gjort bättre? (Alternativt, ifall det redan råkat bli helt perfekt, vad kunde den heuristiska optimeraren ha missat?)
a) (1p)
hur ett fragementeringsschema kan se ut
b) (1p)
hur rekonstruktionsprogrammet (även kallat återskapandeprogrammet) ser ut, givet fragementeringsschemat ovan
c) (2p)
hur en global fråga kan lokaliseras genom att globala relationer ersätts med sina rekonstruktionsprogram
d) (2p)
hur detta relationsalgebrauttryck kan förenklas genom att man reducerar bort tomma deluttryck
| Observera: Välj ut och besvara (högst) sju av de åtta uppgifterna. (Skulle du svara på alla åtta, räknas den med högst poäng bort.) |