These are suggested solutions. There may be other correct solutions. Some of these answers may be more exhaustive than required for full points on the exam.
a)
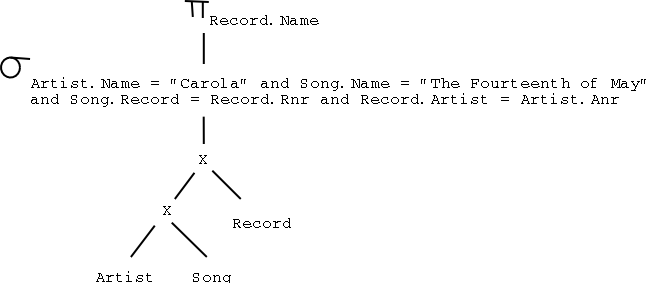
select Record.Name from Record, Artist where Artist.Name = 'Carola' and Artist = Anr;PROJECTRecord.Name [ SELECTName = "Carola"(Artist) JOINArtist = Anr Record ]or, as another example
PROJECTRecord.Name SELECTName = "Carola" and Artist = Anr [ Record X Artist ]
b)
select sum(Length) from Artist, Record, Song where Anr = Artist and Rnr = Record and Artist.Name = 'Carola' and Record.Name = 'Stranger';Fsum(Längd) ( [ SELECTName = "Carola"(Artist) ] JOINArtist = Anr [ SELECTName = "Främling"(Record) ] JOINRnr = Record Song )
c)
select Artist.Name from Artist left outer join Record on Anr = Artist where Rnr is null;orselect Name from Artist where not exists (select * from Record where Artist = Anr);PROJECTAnr, Artist.Namn ( SELECTRnr = null [ Artist LEFT OUTER JOINAnr = Artist Record ] )
The DBMS keeps track of all actions in the database, and whenever someone performs an action that has a trigger on it, for example when someone adds a row to the table Song, the appropriate rule (in that case the rule klu2) will be executed by the DBMS, thus updating the sum of lengths in the table Record.create trigger klu1 for Song after update as if old.Length != new.Length alter table Record set Record.Length = Record.Length - old.Length + new.Length where Rnr = new.Record; create trigger klu2 for Song after insert as alter table Record set Record.Length = Record.Length + new.Length where Rnr = new.Record; create trigger klu3 for Song after delete as alter table Record set Record.Length = Record.Length - old.Length where Rnr = old.Record;
(If you wonder what klu means, it stands for keep length updated.)
b)
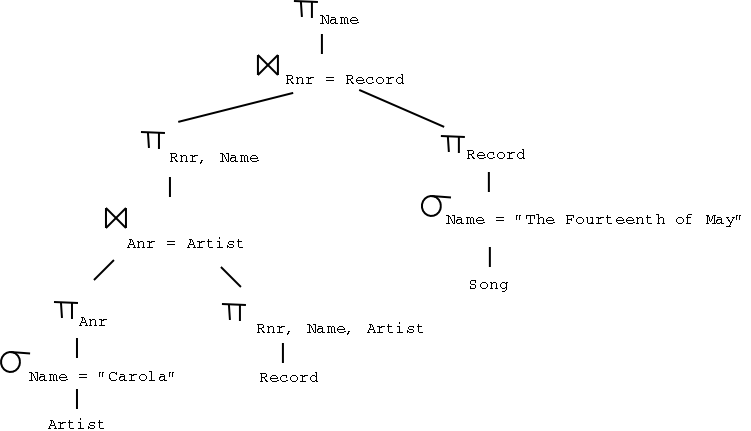
c)
Smaller intermediate results, with fewer tuples and fewer attributes, and therefore less work, since the optimized query tree
d)
With materialization, the entire result from each operation in the tree is created ("materialized") and stored somewhere (perhaps on disk). With pipe-lining, each row in the result is passed on to the next operation, as soon as that row is available. With pipe-lining, the query tree can be executed as a nested loop.
e)
A heuristic query optimizer (of the type covered in this course) creates an execution plan by applying some general rules, such as "select operations should be performed as early as possible". It doesn't take into account different costs of using different algorithms for performing operations such as join and select. It doesn't take into account the size of the data, or the use of different physical storage structures (indexes).
A cost-based query optimizer, on the other hand, has a cost function, which is used to estimate the cost (typically measured in number of disk accesses) of an execution plan. To estimate the cost, the cost function must (and therefore does) take into account the actual or estimated size of the data, which storage structures exist, and also which algorithms will be used.
Choose two of nested-loop join, single-loop join, sort-merge join, and hash join (and perhaps partition hash join and hybrid hash join). See Elmasri/Navathe 3d Ed Section 18.2.3 for descriptions.
b)
Example: In most cases, a single-loop join is much better than a nested-loop join. But this depends on the data and the indexes. There exist cases where a nested-loop join may actually be better.
c)
For disk-based databases, the best join algorithm for a particular case is the one that requires the fewest disk block accesses.
a)
Any reasonable optimizer will first SELECTRnr=17(Record), and then use the single row in that result to perform a JOIN with Artist. This join is in effect a SELECTAnr=...(Artist). So we calculate the times to perform two select operations, on key columns, on the two tables.
There are 1000 rows in the table Record.
Assume a block size of for example 8 kibibyte, i. e. 8192 bytes,
a random block access time of 10 ms,
and a sequential read time of 1 ms.
Also assume that Rnr is 4 bytes, Name is 42 bytes, and Artist is 4 bytes.
This gives a record size of 50 bytes, a blocking factor of 163,
and 7 blocks for the entire file.
On an average, we will find the correct record after reading 4 blocks.
If the file is stored sequentially, it will take 13 ms (10 + (4-1)*1) to read it.
There are 100 rows in the table Artist.
Assume that Anr is 4 bytes, Name is 42 bytes, and Country is 4 bytes.
This gives (again) a record size of 50 bytes, and (again) a blocking factor of 163,
so the entire file fits in a singe block.
It takes 10 ms to read.
Answer: 0.23 ms.
b)
Now there are 106 rows in the Record table,
and 7519 blocks.
On an average we need to read 3760 blocks, which takes 3.760 seconds.
(We ignore that the first read takes 10 ms instead of 1 ms.)
There are 105 rows in the Artist table,
and 614 blocks.
On an average we need to read 307 blocks, which takes 0.307 seconds.
Answer: 4.0 seconds.
c)
Use indexes on:
c)
We assume primary indexes on Record(Rnr) and on Artist(Anr).
First look at the B+-tree index on table Record.
Assume that a disk block pointer requires 4 bytes.
A B+-tree node will have place for 1024 pointers to sub-trees.
Since only two thirds of each node is used, on an average,
the average "effective order" of the tree is 682.
There are 7519 data blocks
(or more, if they are constructed dynamically using the index).
On the first index level, we need 7519 / 1024 + 1 = 8 index blocks.
A second level is enough to connect them,
so there are two levels in the index.
A lookup requires two index block reads, and a data block read,
giving a total of 30 ms.
The index for the Artis table turns out to be similar,
but there are only 614 data blocks.
A single index level is enough to index them.
A lookup requires one index block read, and a data block read,
giving a total of 20 ms.
Answer: 50 ms, or 0.05 seconds.
a)
A CGI script is a separate program, which is started by the web server. The complete output from the CGI script becomes the HTML source code that is sent to the client, and this HTML source is then rendederd by the browser and shown to the user. Since a CGI scripts is a complete, stand-alone program, it can connect to a database and retrievde data in the same way as any other program.
b)
One alternative is to use a web server that understands SQL statements embedded in web pages, sends them to the database server, and replaces each SQL statement with the result of that qyery, before the HTML source is sent to the server. (Other alternatives, such as Java applets and other types of client-side programs, can also be considered.) CGI scripts are inefficient. Starting a new, separate program takes a long time on a computer. Also, if the CGI-generated web page contains output from a database, the CGI-script must open a new connection and log in on the database server, and this has to be done every time the web page is requested. On the other hand, CGI scripts are portable, and easier to test.
ESQL ... ESQL sometimes requires using C and not C++. ESQL is standardized, but less portable than ODBC, and requires re-compilation and sometimes some modification, if you wish to switch to another DBMS. ESQL probably gives the simplest and (if you know ESQL) easiset to read source code. (The truth of that statement can be discussed at length.)
The DBMS's own function library ... The DBMS's own function library may be faster than ODBC, and may allow use of some special features that are not available through ODBC.
A, atomicity. Transactions are atomic, so either all parts of it are performed, or none, even in the face of aborts and system crashes. Without this property, half-finished transactions could remain in the database, for example withdrawing some money from a bank account but never depositing it in another.
C, consistency preserving. If the database is in a consistent state before the transaction, fulfilling all integrity constraints, it will be in a consistent state after the transaction, Without this property, transactions could cause the database to become inconsistent, and perhaps useless.
I, isolation. Concurrently executing transactions are isolated from each other, and intermediate or partial results from one transaction are not allowed to (unduly) effect another transaction. Without this property, transaction could interfere with each other, for example two transaction writing to the same table and ending up with a garbled mix of two sets of data.
D, durability. When a transaction has been committed, the changes it has made in the database should never disappear, even in the face of aborts and system crashes. Without this property, important changes could disappear from the database, for example with money vanishing from your bank account.
b)
| Step | Transaction T1 | Transaction T2 |
|---|---|---|
| 1 | Lock(A) | |
| 2 | Read(A) | |
| 3 | Lock(B) | |
| 4 | Read(B) | |
| 5 | A = A + B | |
| 6 | B = 0 | |
| 7 | Lock(C) | |
| 8 | Read(C) | |
| 9 | B = C | |
| 10 | C = 0 | |
| 11 | Wating to Lock(B)... | |
| 12 | Write(B) | |
| 13 | Unlock(B) | |
| 14 | ...Lock(B) | |
| 15 | Write(B) | |
| 16 | Write(A) | |
| 17 | Unlock(A) | |
| 18 | Write(C) | |
| 19 | Unlock(B) | |
| 20 | Unlock(C) |
The operations after T1:s Unlock(B) may be performed in various different orders.
c)
TS(T1) = 1. TS(T2) = 2.
| Step | Transaction T1 | Transaction T2 | read_TS(A) | write_TS(A) | read_TS(B) | write_TS(B) | read_TS(C) | write_TS(C) |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | |||
| 1 | Read(A) | 1 | 0 | 0 | 0 | 0 | 0 | |
| 2 | Read(B) | 1 | 0 | 1 | 0 | 0 | 0 | |
| 3 | A = A + B | 1 | 0 | 1 | 0 | 0 | 0 | |
| 4 | B = 0 | 1 | 0 | 1 | 0 | 0 | 0 | |
| 5 | Read(C) | 1 | 0 | 1 | 0 | 2 | 0 | |
| 6 | B = C | 1 | 0 | 1 | 0 | 2 | 0 | |
| 7 | C = 0 | 1 | 0 | 1 | 0 | 2 | 0 | |
| 8 | Write(B) | 1 | 0 | 1 | 2 | 2 | 0 | |
| 9 | Write(B) | 1 | 0 | 1 | 2 | 2 | 0 | |
| 10 | Write(A) | 1 | 1 | 1 | 2 | 2 | 0 | |
| 11 | Write(C) | 1 | 1 | 1 | 2 | 2 | 2 |
Both transactions commit after having performed the operations in the given order. No rollback is required. (Operation number 9, T1:s Write(B), is skipped according to Thomas's Write Rule.)
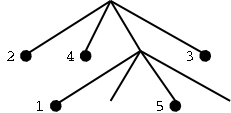
K-d tree, and how it divides the area: