Mitth—gskolan
ITE
Thomas Padron-McCarthy (tpm@nekotronic.se)
Datateknik C, Databaser 5 poðng
onsdag 20 mars 2002
(This exam is available in a Swedish and an English version.)
| Hjðlpmedel: | Inga hjðlpmedel. |
| Poðngkrav: |
Maximal poðng ðr 43.
F—r godkðnt krðvs 21 poðng. |
| Resultat: | Meddelas pÍ kursens hemsida senast onsdag 3 april 2002. |
| Visning: | Tid f—r visning meddelas i samband med resultatet. |
| Examinator och jourhavande: | Thomas Padron-McCarthy, telefon 070-7347013 |
F—rutom anvisningarna pÍ skrivningsomslaget gðller f—ljande:
Scenario till uppgifterna:
Statens Jðrnvðgar, SJ, har en databas f—r biljettbokningar. Som en del i den databasen ingÍr en tidtabell —ver alla tÍglinjer. Den innehÍller tÍgturer, stationer, hur tÍgturerna stannar pÍ stationerna, och tÍg.
En tÍgtur, eller "route" pÍ engelska, ðr, till exempel, tÍget frÍn østersund till Sundsvall varje vardag klockan 09:12. Ett "tÍg" ðr ett verkligt, individuellt tÍg, till exempel det dðr tÍget dðr borta som just nu lðmnar østersund pÍ vðg mot Sundsvall.
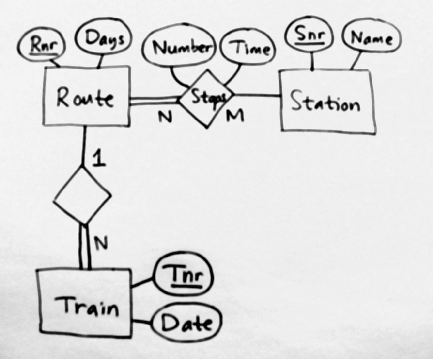
Hðr ðr ett Entity-Relationship-diagram:
Och hðr ðr tabellerna:
Station(Snr, Name)
Stops(Route, Station, Number, Time);
Route(Rnr, Days)
Train(Tnr, Route, Date)
Exempeldata:
Stops
|
Station
| |||||||||||||||||||||||||||||||||||||
Route
|
Train
|
Radantal i tabellerna:
Vilka tÍg stannar pÍ stationen Sundsvalls Vðstra datumet 2002-03-20? Svaret ska innehÍlla tÍgnumret (Tnr).
Vi anvðnder den hðr SQL-frÍgan:
select Train.Tnr
from Station, Stops, Route, Train
where Station.Name = 'Sundsvalls Vðstra'
and Station.Snr = Stops.Station
and Stops.Route = Route.Rnr
and Route.Rnr = Train.Route
and Train.Date = '2002-03-20'
a) (1p) G—r den systematiska —versðttningen av SQL-frÍgan till det initiala frÍgetrðdet, och rita upp trðdet!
b) (1p) Skriv detta initiala frÍgetrðd som ett relationsalgebrauttryck (alltsÍ inte uppritat som ett trðd).
c) (2p) En heuristisk frÍgeoptimerare g—r om frÍgetrðdet till en mer effektiv form. Rita upp resultatet!
d) (2p) F—rklara varf—r detta nya trðd ðr mer effektivt ðn det initiala frÍgetrðdet. Vilka f—rbðttringar har gjorts? Varf—r gÍr frÍgan (f—rmodligen) snabbare att k—ra nu?
e) (1p) Vilka brister finns med en heuristisk frÍgeoptimerar av den hðr typen? Om man i stðllet anvðnder kostnadsbaserad frÍgeoptimerare, kan en del av bristerna —vervinnas. Hur?
Jag vill Íka frÍn Sundsvalls Vðstra till Stockholms Central datumet 2002-03-20. Vilka tider kan jag Íka?
Vi anvðnder den hðr SQL-frÍgan:
select firststop.Time
from Station as firststn, Station as laststn,
Stops as firststop, Stops as laststop, Route, Train
where firststn.Name = 'Sundsvalls Vðstra'
and firststn.Snr = firststop.Station
and firststop.Route = Route.Rnr
and laststn.Name = 'Stockholms Central'
and laststn.Snr = laststop.Station
and laststop.Route = Route.Rnr
and Route.Rnr = Train.Route
and Train.Date = '2002-03-20'
and firststop.Number < laststop.Number
Formulera SQL-frÍgan som ett relationsalgebrauttryck pÍ valfritt sðtt.
(Om du vill kan du i stðllet rita den som ett frÍgetrðd, men det ðr inte n—dvðndigt.)
a) (4p) Vilka index b—r man skapa?
b) (1p) Kan DBA:n g—ra nÍgot mer, f—rutom att skapa index, f—r att snabba upp frÍgorna?
G—r rimliga antaganden om diskblocksstorlek mm, och rðkna ut hur lÍng tid frÍgan i genomsnitt kommer att ta att k—raselect Date from Train where Tnr = 4711
a) med tabellen Train lagrad som en osorterad heap, och inga index
b) med ett primðrindex i form av ett B+-trðd pÍ attributet Tnr, och inga andra intressanta lagringsstrukturer
c) med ett sekundðrindex i form av en hashtabell pÍ attributet Tnr, och inga andra intressanta lagringsstrukturer.
a) (1p) Varf—r fungerar vanliga index, som B+-trðd och hashtabeller, inte sÍ bra med tvÍdimensionella data, som kartor?
b) (2p) Ge exempel pÍ en datastruktur som man kan anvðnda i stðllet, och beskriv kort hur den fungerar.
a) (1p) øversðtt den givna SQL-frÍgan till ett relationsalgebrauttryck.select Station.Name, count(*) from Station, Stops where Station.Snr = Stops.Station group by Station.Name
b) (1p) Det finns nÍgra nybyggda stationer, dðr inga tÍgturer stannar ðn. De stationerna kommer inte med alls i resultatet av frÍgan ovan. Skriv en ny SQL-frÍga, dðr ðven de nya stationerna finns med i resultatet, med noll i kolumnen f—r antalet tÍgturer som stannar.
c) (1p) øversðtt den nya SQL-frÍgan till ett relationsalgebrauttryck.
Station
| Snr | Name | Country |
|---|---|---|
| 1 | Sundsvalls Central | Sweden |
| 2 | Sundsvalls Vðstra | Sweden |
| 2877 | Trondheim | Norway |
| 4876 | Notting Hill Gate | UK |
| 6777 | New Delhi East | India |
| ... | ... | ... |
Vi vill ocksÍ distribuera databasen. Varje land fÍr sitt eget fragment av tabellen Station, med hjðlp av primðr horisontell fragmentering baserad pÍ attributet Country:
a) (1p) Ange fragmenteringsschemat f—r relationen Stops
b) (0.5p) Ange Íterskapandeprogrammet ("reconstruction program") f—r relationen Station
b) (0.5p) Ange Íterskapandeprogrammet f—r relationen Stops
d) (1p) Vi vill veta den tidigaste tid pÍ dagen som ett tÍg nÍgonsin stannar pÍ Sundsvalls Central i Sverige (Sweden). Vi anvðnder den hðr SQL-frÍgan:
øversðtt detta till ett effektivt relationsalgebrauttryck, med de globala relationerna.select min(Stops.Time) from Station, Stops where Station.Snr = Stops.Station and Station.Name = "Sundsvalls Central" and Station.Country = "Sweden"
e) (1p) Lokalisera ("localize") relationsalgebrauttrycket ovan genom att byta ut de globala relationerna mot deras Íterskapandeprogram.
f) (1p) F—renkla det relationsalgebrauttrycket genom att reducera bort deluttryck som ger tomma resultat.
a) (1p) Ibland anvðnds lðs- och skrivlÍs, i stðllet f—r vanliga binðra lÍs. Hur fungerar lðs- och skrivlÍs?
b) (1p) Varf—r vill man anvðnda lðs- och skrivlÍs i stðllet f—r vanliga binðra lÍs?
c) (2p) Varf—r ðr lÍsning svÍrare i en distribuerad databas ðn i en centraliserad databas? Hur g—r man? Blir det nÍgra sðrskilda svÍrigheter om man vill ha lðs- och skrivlÍs i en distribuerad databas?
<table border="1">
<tr><th>Number</th> <th>Name</th></tr>
<emit source="sql" host="foodbase" query="select id, name
from person order by id">
<tr><td>&_.id;</td> <td>&_.name;</td></tr>
</emit>
</table>
a) (1p)
F—rklara kort vad som hðnder inuti webbservern nðr den st—ter pÍ en SQL-frÍga
som den hðr.
b) (2p) Det ðr praktiskt att kunna stoppa in SQL-frÍgor i HTML-koden sÍ hðr, men finns det andra f—rdelar jðmf—rt med alternativen? Och vilka ðr alternativen?