Mitthˆgskolan
ITE
Thomas Padron-McCarthy (tpm@nekotronic.se)
Datateknik C, Databaser 5 po‰ng
Wednesday March 20, 2002
(This exam is available in a Swedish and an English version.)
| Utilities: | None. |
| Points: |
Maximum 43 points.
21 points required to pass. |
| Results: | Will be posted on the course home page, no later than Wednesday April 3, 2002. |
| Walk-thru: | Time for walk-thru will be posted along with the result. |
| Examiner and teacher on duty: | Thomas Padron-McCarthy, telephone 070-7347013 |
In addition to the instructions on the cover of the test, please also:
Scenario for the problems:
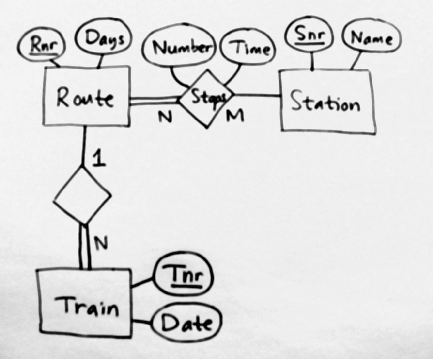
The Swedish State Railroads, Statens J‰rnv‰gar, abbreviated SJ, has a database for ticket bookings. As a part of that database, there is a time table for all train routes. It contains train routes, train stations, how the routes stop at the stations, and trains.
A "route" is, for example, the train from ÷stersund to Sundsvall every weekday at 09:12. A "train" is an actual individual train, such as that train over there that just now leaves from ÷stersund to Sundsvall.
Here is an Entity-Relationship diagram:
And here are the tables:
Station(Snr, Name)
Stops(Route, Station, Number, Time);
Route(Rnr, Days)
Train(Tnr, Route, Date)
Example data:
Stops
|
Station
| |||||||||||||||||||||||||||||||||||||
Route
|
Train
|
Number of rows in the tables:
Which trains stop at the station Sundsvalls V‰stra on the date 2002-03-20? The result should consist of the train number (Tnr).
We use this SQL query:
select Train.Tnr
from Station, Stops, Route, Train
where Station.Name = 'Sundsvalls V‰stra'
and Station.Snr = Stops.Station
and Stops.Route = Route.Rnr
and Route.Rnr = Train.Route
and Train.Date = '2002-03-20'
a) (1p) Do the systematic translation from the SQL query to the initial query tree, and draw the tree.
b) (1p) Write that initial query tree as a relational algebra expression (that is, not drawn as a tree).
c) (2p) A heuristic query optimizer transforms the query tree to a more efficient form. Draw the resulting tree!
d) (2p) Explain why this new tree is more efficient than the initial tree. Which improvements have been made? Why is the execution of the query (probably) faster now?
e) (1p) Which shortcomings does a heuristic query optimizer of this type have? By using a cost-based query optimizer, some of those shortcomings can be addressed. How?
I want to go from Sundsvalls V‰stra to Stockholms Central on the date 2002-03-20. At which times can I leave?
We use this SQL query:
select firststop.Time
from Station as firststn, Station as laststn,
Stops as firststop, Stops as laststop, Route, Train
where firststn.Name = 'Sundsvalls V‰stra'
and firststn.Snr = firststop.Station
and firststop.Route = Route.Rnr
and laststn.Name = 'Stockholms Central'
and laststn.Snr = laststop.Station
and laststop.Route = Route.Rnr
and Route.Rnr = Train.Route
and Train.Date = '2002-03-20'
and firststop.Number < laststop.Number
Formulate the SQL query as a relational algebra expression,
in any way that gives a correct result.
(If you want to, you can write it as a query tree, but that is not required.)
a) (4p) Which indexes should we create?
b) (1p) Can the DBA do something else, besides crating indexes, to speed up the queries?
State reasonable assumptions concerning disk block size etc, and calculate how long the execution of the query will take, on an average.select Date from Train where Tnr = 4711
a) with the table Train stored as an unsorted heap, and no indexes
b) with a B+-tree primary index on the attribute Tnr, and no other interesting storage structures
c) with a secondary index in the form of a hash table, on the attribute Tnr, and no other interesting storage structures
a) (1p) Why do the usual index structures, such as B+ trees and hash tables, not work well with two-dimensional data, such as maps?
b) (2p) Give an example of a data structure that is suitable for two-dimensional data, and describe in short how it works.
a) (1p) Translate this SQL query to a relational algebra expression.select Station.Name, count(*) from Station, Stops where Station.Snr = Stops.Station group by Station.Name
b) (1p) There are some newly-built stations where no trains stop yet. Those stations are not present at all in the result of the query above. Write a new SQL query, where the new stations too are present in the result, with zero in the column for the number of train routes that stop.
c) (1p) Translate the new SQL query to a relational algebra expression.
Station
| Snr | Name | Country |
|---|---|---|
| 1 | Sundsvalls Central | Sweden |
| 2 | Sundsvalls V‰stra | Sweden |
| 2877 | Trondheim | Norway |
| 4876 | Notting Hill Gate | UK |
| 6777 | New Delhi East | India |
| ... | ... | ... |
We also want to distribute the database. Each country gets its own fragment of the Station table, using primary horizontal fragmentation based on the attribute Country:
a) (1p) Give the fragmentation schema for the relation Stops
b) (0.5p) Give the reconstruction program for the relation Station
c) (0.5p) Give the reconstruction program for the relation Stops
d) (1p) We want to know the earliest time of day ever that a train stops at Sundsvalls Central in Sweden. We use this SQL query:
Translate this to an efficient relational algebra expression, using the global relations.select min(Stops.Time) from Station, Stops where Station.Snr = Stops.Station and Station.Name = "Sundsvalls Central" and Station.Country = "Sweden"
e) (1p) Localize the above relational algebra expression by replacing the global relations with their reconstruction programs.
f) (1p) Simplify that relational algebra expression by removing parts that give empty results.
a) (1p) Sometimes we use read- and write-locks, instead of plain binary locks. How do read- and write-locks work?
b) (1p) Why do we use read- and write-locks, instead of plain binary locks?
c) (2p) Why is locking more difficult in a distributed database than in a centralized database? How do you do it? Are there any special difficulties if you want read- and write-locks in a distributed database?
<table border="1">
<tr><th>Number</th> <th>Name</th></tr>
<emit source="sql" host="foodbase" query="select id, name
from person order by id">
<tr><td>&_.id;</td> <td>&_.name;</td></tr>
</emit>
</table>
a) (1p)
Explain, in short, what happens "behind the scenes" in the web server
when it encounters an SQL query like this one.
b) (2p) It is convenient to be able to put SQL queries in the HTML code like this, but are there other advantages too, compared to the alternatives? And which are the alternatives?