 snr, snamn
[ (
snr, snamn
[ ( 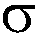 knamn = "Databasteknik C" (kurs)
knamn = "Databasteknik C" (kurs) 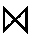 knr = kurs godkänd ) student = snr student ]
knr = kurs godkänd ) student = snr student ]
These are suggested solutions. There may be other correct solutions. Some of these answers may be more exhaustive than required for full points on the exam.
a)
snr, snamn
[ ( knamn = "Databasteknik C" (kurs) knr = kurs godkänd ) student = snr student ]
Comment: Since snr is primary key in student, and knr is primary key in kurs, and reference attributes refer to primary keys, we know that the attributes student and kurs in godkänd are numbers and not names.
b)
L ![]() snr, snamn
[ ( knamn = "Databasteknik C" (kurs) knr = kurs läser ) student = snr student ]
snr, snamn
[ ( knamn = "Databasteknik C" (kurs) knr = kurs läser ) student = snr student ]
G ![]() snr, snamn
[ ( knamn = "C++" (kurs) knr = kurs godkänd ) student = snr student ]
snr, snamn
[ ( knamn = "C++" (kurs) knr = kurs godkänd ) student = snr student ]
Result ![]() L - G
L - G
c)
snr, snamnFcount(*)
( student snr = student läser )
d)
snr, snamnFcount(kurs)
( student 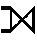 snr = student läser )
snr = student läser )
e)
EK ![]() knr
( inamn = "Elektromekanik" (kurs) inr = institutionkurs )
knr
( inamn = "Elektromekanik" (kurs) inr = institutionkurs )
SK ![]() snr, snamn, kurs
( student snr = student läser )
snr, snamn, kurs
( student snr = student läser )
Result ![]() SK
/
[
SK
/
[ 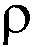 (kurs)(EK) ]
(kurs)(EK) ]
a)
PROJECTsnr, snamn [ ( SELECTknamn = "Databasteknik C" (kurs) JOINknr = kurs godkänd ) JOINstudent = snr student ]
b)
L <- PROJECTsnr, snamn [ ( SELECTknamn = "Databasteknik C" (kurs) JOINknr = kurs läser ) JOINstudent = snr student ]
G <- PROJECTsnr, snamn [ ( SELECTknamn = "C++" (kurs) JOINknr = kurs godkänd ) JOINstudent = snr student ]
Result <- L - G
c)
snr, snamnFcount(*) ( student JOINsnr = student läser )
d)
snr, snamnFcount(kurs) ( student LEFT OUTER JOINsnr = student läser )
e)
EK <- PROJECTknr ( SELECTinamn = "Elektromekanik" (kurs) JOINinr = institutionkurs )
SK <- PROJECTsnr, snamn, kurs ( student JOINsnr = student läser )
Result <- SK DIVISION [ RENAME(kurs)(EK) ]
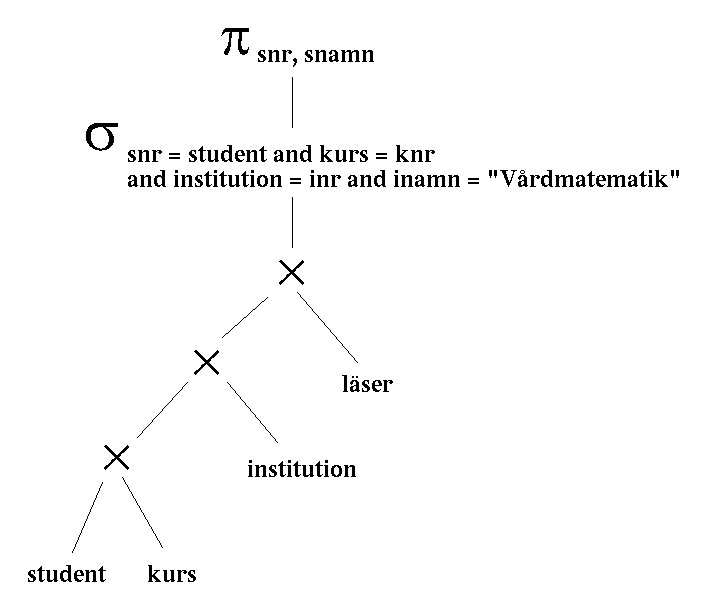
snr, snamn
snr = student and kurs = knr and institution = inr and inamn = "Vĺrdmatematik"
(student  kurs institution läser)
kurs institution läser)
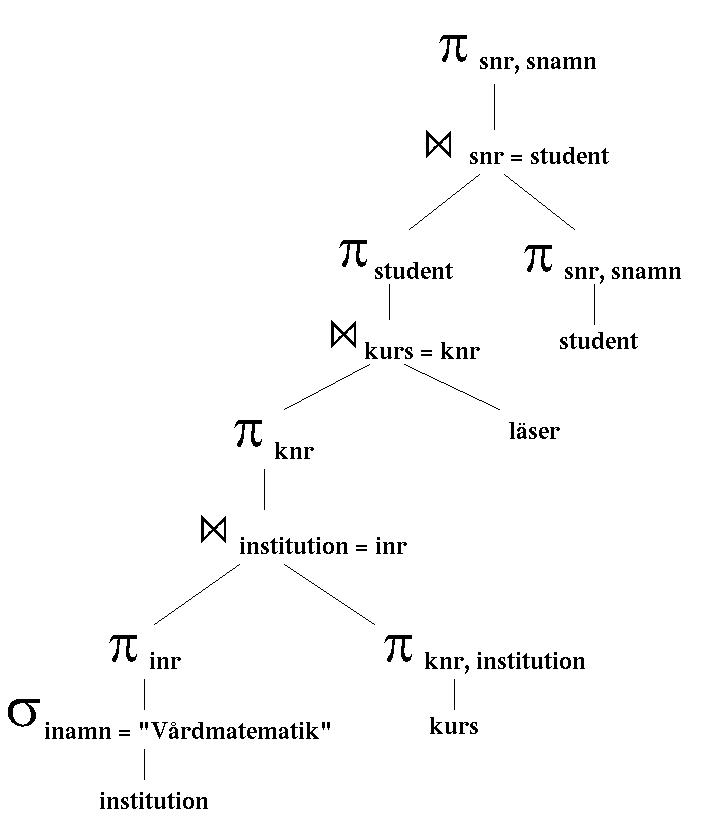
b)
 c)
c)
The optimizer can be exhaustive, and examine all possible (and reasonable) execution plans, and thus always find the cheapest solution. It can also be non-exhaustive, and just examine a subset, which could be randomly chosen, but usually according to some optimization algorithm such as hill climbing.
The cost function must take into account the actual or estimated size of the data. A heuristic query optimizer (of the type covered in this course) only creates an execution plan by applying some genereal rules, such as "select operations should be performed as early as possible". Such an heuristic query optimizer has no way of knowing, e. g., if the table student is much larger than the table institution, which can be important to know when choosing a good execution plan.
A cost-based query optimizer can also compare the cost of different algorithms for join and select operations, and also take physical storage structures into account.
ODBC is a call-level interface, where you write SQL queries as strings in procedure calls, while ESQL attempts to integrate SQL with the host language. In ESQL, the embedded SQL queries are translated to procedure calls (similar to those in ODBC) by a pre-processor. You have to write more code in ODBC.
ODBC is available for more DBMSs than ESQL. ODBC is also more flexible: an ODBC program can talk to several databases, of the same or of different types of DBMSs, simultaneously. This is difficult to do in ESQL. You can change the databases, or types of DBMSs, that an ODBC program talks to, without re-compiling or even re-linking the program.
b)
knr -> knamn
knr -> institution
c) 1NF
d) Problems due to low normalization:
b) None.
c)
student -> läser_kurs
student -> godkänd_kurs
d) BCNF
e) Problems due to low normalization:
|
Comment:
Problem 6 is about 4NF,
and question c should be a strong hint to this.
But by ignoring that,
it is also possible to intrepret the given information
as the attribute "godkänd_kurs" being a boolean value,
which is set to True when the student passes the course.
This would then give the following answers:
a) student + läser_kurs b) (student + läser_kurs) -> godkänd_kurs c) No non-trivial multi-valued dependencies, but there is a trivial multi-valued dependency student -> (läser_kurs, godkänd_kurs) d) BCNF, and also 4NF e) None. |
An object-oriented DBMS, sometimes called a "first-generation object-oriented" DBMS, is an object-oriented programming language (typically C++, Java or Smalltalk) with database functionality (such as persistence and some transaction functionality) added. There is no declarative query language (but OQL, an object query language, has been proposed), and the programmer has to navigate through the database with pointers, similar to any C++ program.
An object-relational DBMS, or "second-generation object-oriented" DBMS, is a DBMS with object-oriented functionality (such as inheritance). It has extensive database functionality, such as a query language, views, and advanced transaction management. Some object-relational DBMSs are relational DBMSs, with some rather limited object-oriented functionality added. This has nothing (or at least very little) to do with the Entity/Relationship model.
Object-oriented databases are suitable for applications with few, complicated transactions on few, complicated data, such as CAD systems. They can be very efficient, but unsafe, when working with checked-out data in the application's memory space. Long transactions (lasting hours or days) may be better handled by object-oriented databases, and chek-in/check-out transactions.
Similar to relational databases, object-relational databases are more suited for applications with many simple transactions on many simple data. Due to the declarative query language, object-relational databases have better data independence, making them suitable for applications where the schema changes frequently. If all you want is persistent storage for the objects in your object-oriented program, then an object-relational DBMS is probably overkill, and therefore inefficient.
| Comment: Unfortunately there were some misprints in this exam question. All references to the table student and its attributes should really be the table kurs and its attributes. This could be guessed from the context, but the point limit for a passing grade has still been lowered in proportion to the points from this query. |
None of the specified indexes can be used in the question. We assume the most efficient execution of this query, which means that we first read the table institution sequentially to find the row for the department "Vĺrdelektronik", and then we use the department number "inr" when sequentially reading through the table kurs.
The numerical calculations in this problem are allowed to be very approximative.
Some reasonable assumptions:
Answer: 0.5 seconds, in both a and b.
Strict two-phase locking prevents cascadings rollbacks. A cascading rollback happens when the rollback of a transaction forces another, unrelated, transaction to be rolled back too. This happens if a transaction, T1, has written a data object, X, and then released its lock on X before T1 has committed. Another transaction, T2, may then read X. If T1 is aborted after T2's read, and the roll-back changes X back to the old value, T2, that depends on the value written by T1, is now invalid and has to be rolled back.
When the DBMS re-starts after a crash, we have two things: the data on the hard disk (called the materialized database), and the log file. The log file contains both committed transactions (with a commit record written in the log file) and uncommitted transactions (without a commit record written in the log file). Both committed and uncommitted transcations may hava made changes in the materialized database (if we assume immediate update). Not all changes, even from the committed transactions, are guaranteed to actually have made it into the materialized database.
To ensure durability, all write operations from all committed transactions must be re-done. Those write operations can be found in the log file.
To ensure atomicity, all write operations from all uncommitted transactions must be un-done. (Not needed if deferred update is used.) Those write operations can be found in the log file.
During recovery, it is only necessary to re-do and un-do write operations from after the last checkpoint.
After a disk crash, when there is no materialized database, the database is restored from backup, and then all committed transactions from the entire log file (from the time of the back-up) have to be re-done.
b) XML, the Extensible Markup Language, is a data representation format that looks a bit like HTML. It can be used on the web, or in other places where data needs to be stored or communicated.
c) A k-d tree is a type of two-dimensional index. It is a binary tree, where the levels in the tree alternate between two dimensions. The root node in the tree could, for example, split a map along the x axis, the nodes in the second level split the map along the y axis, the nodes in the third level split the map again along the x axis, and so on. There are variants of k-d trees that are based on B-trees instead of binary trees.
d) CORBA, the Common Object Request Broker Architecture. A standard for communication between object-oriented applications, letting them communicate across a network, independent of operating system, programming language, and the type of network.
e) RAID, Redundant Array of Independent Disks. We let several physical hard disks work in parallell, combining them into one "logical" hard disk. There are several types of RAID, and depending on which one we use we can increase either data transfer rate (through data striping), or security agains disk crashes (through various types of redundancy), or both.
CGI scripts are inefficient. Starting a new, separate program takes a long time on a computer. Also, if the CGI-generated web page contains output from a database, the CGI-script must open a new connection and log in on the database server, and this has to be done every time the web page is requested.
The alternative is to let the web server itself connect to the database, without starting a separate program. An example of this is Roxen Webserver, which lets you embed SQL statements in normal HTML or XML web pages. The web server then sends the SQL query to the database, and inserts the output from the query in the web page.
This can be more efficient than CGI scripts, since we don't have to launch a separate program. Also, the web server can keep the connection to the database server open, and re-use the same session for all queries.
b) student = S1
 S2
S3
S2
S3
c)
select knr, knamn from student, läser, stad where stad = 'Östersund' and snr = student and kurs = knrd)
knr, knamn
[ stad = "Östersund"(student)
snr = student läser
kurs = knr kurs ]
e)
knr, knamn
[ stad = "Östersund"( S1
S2
S3 )
snr = student läser
kurs = knr kurs ]
f)
Since no students from Östersund will be present in fragments S1 and S3, we can reduce them from the expression, and since no students other than from Östersund will be present in fragment S2, we don't need the select operation:
knr, knamn
[ S1
snr = student läser
kurs = knr kurs ]